Welcome to caution's Blog!
안녕하세요, iOS 개발자 김주희입니다.-
Django Study Day 1
안녕하세요! caution입니다.
정말 오랜만의 포스팅이네요. 취뽀한 이후로 너무너무너무 바빴어요 ㅠㅠ….. 이전 CoreData Tutorial도 마무리해야하는데 오늘은 다른 포스팅을 들고왔어요 :)
최근에
Django스터디에 참여하게 됐습니다!python은 1도 모르지만, 이전부터 한 번 제대로 배워보고 싶었던 거라서 꾸준히 포스팅할 수 있었으면 좋겠네요.개발환경 구축하기
먼저
Django가 무엇인지 알아보기 앞서,python개발환경을 먼저 구축해야합니다. 저도python을 잘 모르지만, 일단 개발 언어라는 것은 들어보셨을 것 같아요!python버전별, 프로젝트별 사용해야 하는 환경이 다를 수 있는데요, 그렇기 때문에 하나의 PC에서 다양한python프로젝트들을 진행해야 한다면 가상환경으로 분리하여 사용할 것을 추천합니다.제가 잘 알면 참 좋겠지만 (후훗) 저도 다른 분의 포스팅을 보고 따라했어요. :) 함께 참고하실 수 있도록 링크 남겨봅니다.
python 프로젝트 가상환경 생성하기
위의 포스팅을 잘 따라하셨다면, 파이썬 버전 관리 시스템인
pyenv와, 가상환경 분리에 필요한pyenv-virtualenv가 설치되었을 것 같네요.이제 새로운
python프로젝트를 위한 가상환경을 만드는 것으로, 포스팅을 본격적으로 시작해봅시다 :)새로운 가상환경 생성
python버전은 3.6.8을 사용하고, 이름은 djangogirls-env 인 가상환경을 만들어봅시다.$ pyenv virtualenv 3.6.8 djangogirls-env원하는 위치에서 가상환경 구동시키기
이제 본격적으로 프로젝트를 진행할 Directory를 만들고, 가상환경을 동작시켜서 프로젝트를 시작할 준비를 마무리해보죠.
이번 Django 스터디에서는 가장 최상위 루트를 projects로 명명하기로 했어요. 그리고 가장 첫 번째 프로젝트의 이름은 djangogirls입니다. 여기에 맞게 폴더구조를 먼저 구성합시다.
$ cd ~/ $ mkdir projects $ cd projects $ mkdir djangogirls $ cd djangogirls이제
djangogirls에서, 앞서 만들었던djangogirls-env가상환경을 구동시킵시다.$ pyenv local djangogirls-env오, 위의 명령어를 치고 나면 사용하고 있는
console이 이전과 조금 달라진 것을 알아채셨나요?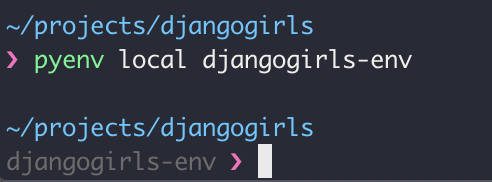
명령어를 치기 전에는 일반적인 디렉토리를 탐색하는 콘솔이었지만, 명령어를 입력하고 나니 python` 가상환경 안으로 들어왔습니다!
가상환경 확인하기
앞서 말했다시피 다양한
python가상환경을 구축할 수 있기 때문에, 현재 가상환경이 어떤 걸 구동한 건지 궁금할 때가 있겠죠? 그럴땐pyenv version을 사용합니다.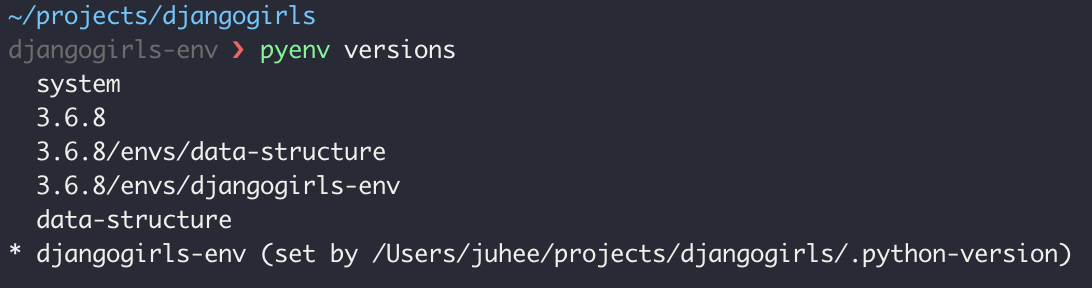
오.. 생각보다 많은 가상환경이 있었어요 XD. 그 중 현재 구동되어 있는 가상환경 앞에 * 표시가 붙습니다.
그럼 이 가상환경에 어떤 패키지가 포함되어 있는지 확인하려면 어떻게 해야할까요? 요건 가상환경과 상관없이, python package manager 명령어인
pip를 사용하여 알 수 있습니다.$ pip listPyCharm
python프로젝트를 진행하면서 사용할 IDE는 PyCharm을 사용합니다.jetbrains의 PyCharm은 학생 이메일 계정으로 인증하면 1년간 무료로 사용할 수 있으니 참고하세욧!
DB Browser for SQLite
백엔드 프로젝트를 진행하면 자연스럽게 Database를 다루게 되겠죠? Database GUI 툴인 DB Browser for SQLite를 설치해줍시다!
Django
쟝고 스터디를 하려면 쟝고프레임워크를 깔아야겠죠! 위의 파이썬 개발환경 구축이 정상적으로 완료되었다면,
pip명령어를 통해서 Django 를 설치할 수 있습니다.$ pip install Django이제 개발환경 셋팅이 끝났다면, 본격적으로 Django 스터디를 시작하죠 :)
Django 란?
Django girls에 따르면,
Django는 파이썬으로 만들어진 무료 오픈소스 웹 애플리케이션 프레임워크(web application framework)입니다. 쉽고 빠르게 웹사이트를 개발할 수 있도록 돕는 구성요소로 이루어진 웹 프레임워크랍니다.
웹사이트를 구축할 때, 비슷한 유형의 요소들이 항상 필요한데요, Django에는 회원가입, 로그인, 로그아웃과 같이 사용자 인증을 다루는 방법이나 웹사이트의 관리자 패널, 폼, 파일 업로드 등 웹 프로젝트에서 바로 사용할 수 있는 구성요소들을 갖춘 프레임워크입니다.
개인적으로는 관리자 페이지를 만들지 않아도 된다는 점이 제일 끌렸어요! :)
Django Girls
저희의 첫 번째 장고 프로젝트로 Django Girls를 따라하기로 했어요. 다행히 한국어이고, 기초가 부족한 분들을 위해서 하나부터 열까지 다 설명해주고 있어서 혼자서도 할 수 있도록 만들어진 매우 훌륭한 튜토리얼입니다.
그래서 이번 주 스터디(그리고 포스팅)의 목표는 다음과 같습니다.
Django프로젝트 환경을 구축한다.Django프로젝트로 웹 서버를 띄운다.- 프로젝트의 모듈을 생성한다.
- 프로젝트에 사용될 Model을 생성하고 DB에 추가한다.
- 추가 URL을 등록하고 View를 랜더링한다.
- Model을 관리할 수 있는 관리자페이지를 만든다.
그리고 숙제는 Django Girls를 혼자서 진행해보는 것입니다. 하하하. 뭔가 갈 길이 멀지만 후다다다닥 해볼게용.
Django Project 생성하기
자 이제 Django 프로젝트를 만들어봅시다. 프로젝트의 이름은
mysite로 하고, 위치는 현재 위치(~/projects/djangogirls)에서 시작하죠.$ django-admin startproject mysite .그리고 나서 현재 위치를 살펴보면?!
$ ls -al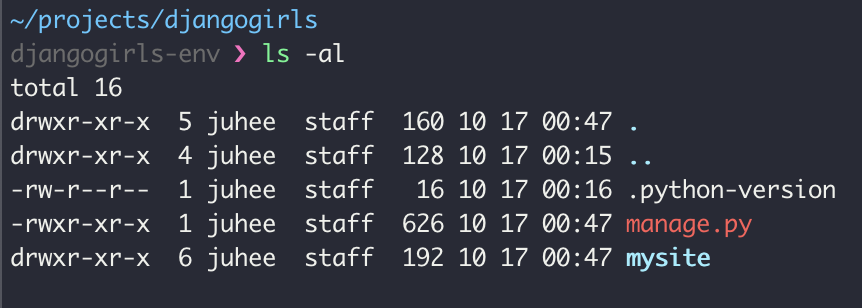 짜잔~ django 프로젝트에 필요한 파일들이 설치되었습니다. 그리고 이제 이 폴더를 PyCharm에서 열어보죠.
짜잔~ django 프로젝트에 필요한 파일들이 설치되었습니다. 그리고 이제 이 폴더를 PyCharm에서 열어보죠.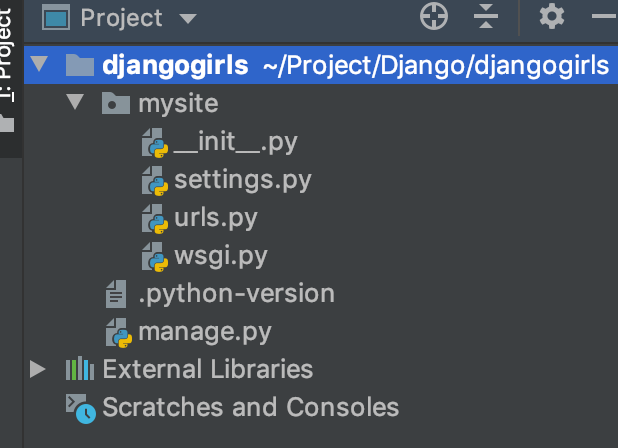
간단하게 살펴보면, 프로젝트를 생성한 가장 최상위 프로젝트 루트인
djangogirls가 있고, 프로젝트를 시작할 때 적어주었던mysite라는 이름을 가진 패키지가 있습니다. 그리고 파이썬 관련 버전을 나타내는 듯한.python-version파일이 있고,manage.py파일이 있군요.manage.py
manage.py는 스크립트 파일로, 사이트 관리를 도와주는 역할을 합니다. 이 스크립트로 다른 설치 작업 없이, 컴퓨터에서 웹 서버를 시작할 수 있습니다. Django 프로젝트를 진행하면서 필요한 기능 (Application 추가, Database migration, admin 사용자 추가 등등)들에 대한 스크립트를 포함하고 있습니다.settings.py
mysite패키지 하위에는settings.py라는 파일이 있는데요, 이 파일은 웹사이트와 관련된 설정을 작성하는 파일입니다.처음 프로젝트를 생성한 상태에서 이 파일을 열어보게 되면 엄청난 양의 기본코드들이 들어가 있습니다. 이 프로젝트에 필요한 django 어플리케이션들이나, middleware, Database, language-code 등 다양한 기본 설정들이 들어가 있습니다.
추가적으로 필요한 설정들이 있다면 여기에서 수정할 수 있습니다.
urls.py
urls.py는 왠지 이름에서 부터 그 역할을 유추할 수 있을 것 같죠? 바로 이 프로젝트의 url들을 관리하는 파일입니다. 한 번 열어보면?
오잉, 아무것도 만들지 않았는데 이미
admin이라는 url path가 있군요. 이미 우릴 위해 만들어진 admin 페이지가 있는 건 아닐까요?Django 서버 구동하기
이 django 프로젝트를 실제 브라우저환경에서 보려고 하면 어떻게 해야할까요? 아까
manage.py를 설명하면서 이 스크립트 파일을 사용하면 별도 설치 없이 웹 서버를 시작할 수 있다고 했습니다 :) 한 번 실제로 그렇게 되는지 살펴보죠.$ python manage.py runserver팁! PyCharm 하단 툴바의 Terminal을 누르면 console을 사용할 수 있습니다. PyCharm 과 다른 console 프로그램을 열지 않아도 되서 간편하죠?
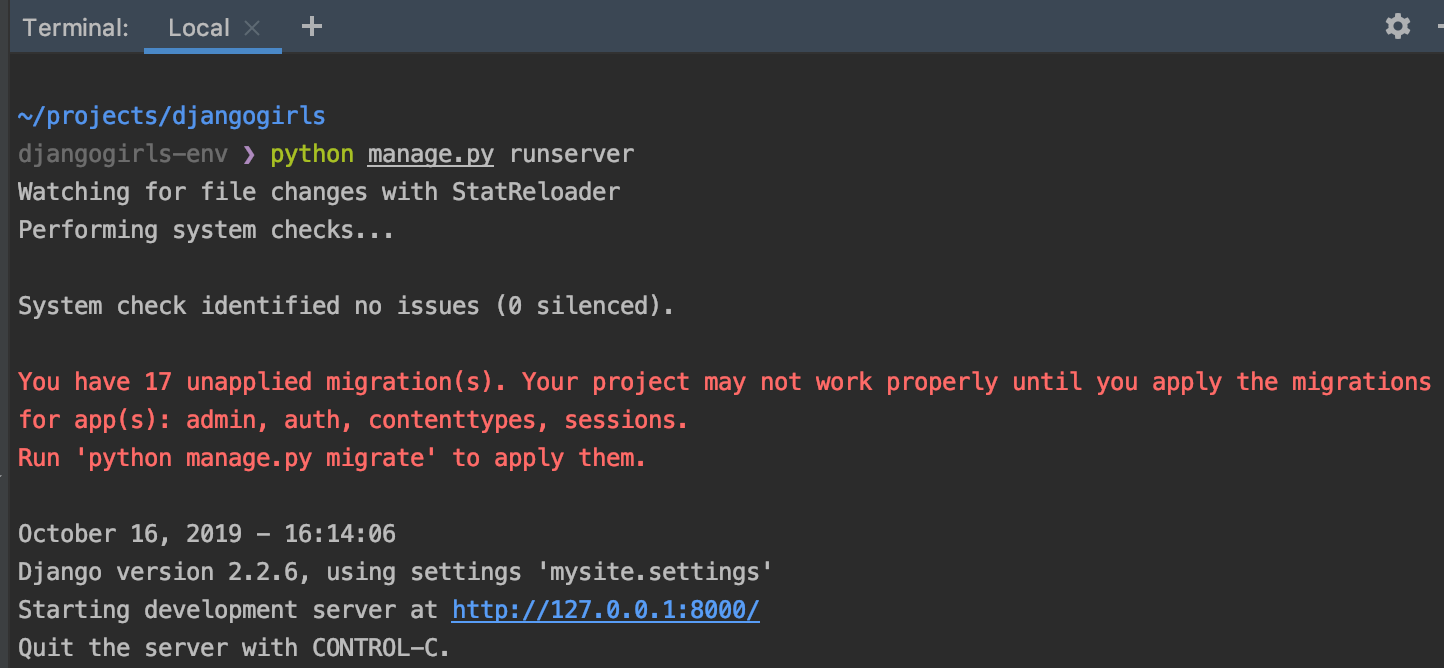
오옹.. 문구를 살펴보니 파일 변화를 StatReloader가 지켜본다고 이야기 하고, 시스템 체크가 끝난다음… 알 수 없는 경고 문구가 뜬 다음 http://127.0.0.1:8000/에 서버가 시작했다고 알려주네요!
친절하게 서버를 종료하려면
Control + C를 누르라고도 적혀있어요 XD진짜 서버가 떳는지 궁금하다면? http://127.0.0.1:8000/를 열어봅시다!
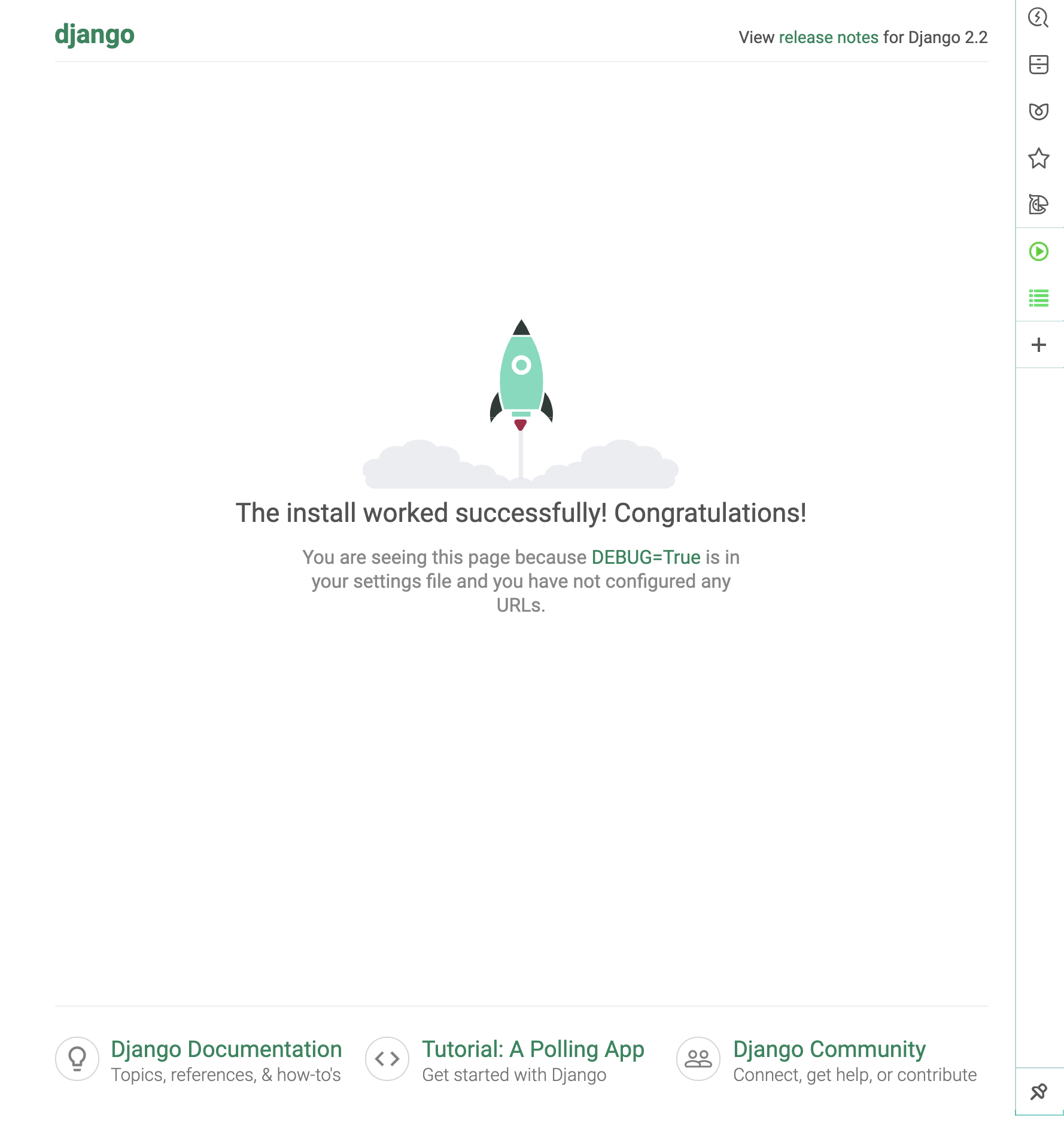
오.. 아무것도 하지 않았는데 Django 프로젝트를 시작한 것 만으로도 웹 서버를 띄우고, localhost에 admin페이지가 뜨는군요!
신기신기신기..! 과거 Tomcat 열심히 깔아서 쓰던 유저는 그저 마냥 신기합니다. 앞으로의 스터디가 더 기대되요 :)
Blog Application 만들기
Django 에서 Application 이란?
하나의 웹 프로젝트는 다양한 단위로 세분화할 수 있습니다. 예를 들어 네이버 사이트를 만든다고 생각했을 때 네이버 검색, 블로그, 카페, 쇼핑 등등 하나로 개발하기에는 너무나도 큰 규모의 프로젝트를 진행해야 한다면 각 기능별로 나누어 볼 수 있겠죠. 그리고 그 각각의 기능들이 Django 에서는 Application이 됩니다.
Application 추가하기
한 프로젝트에 다수의 Application들이 추가하려면 어떻게 해야할까요? 앞서 소개되었던
manage.py가 이미 Application을 생성하는 명령어를 가지고 있습니다. blog Application을 추가하기 위해manage.py에 포함된startapp이라는 명령어를 사용해봅시다.$ python manage.py startapp blog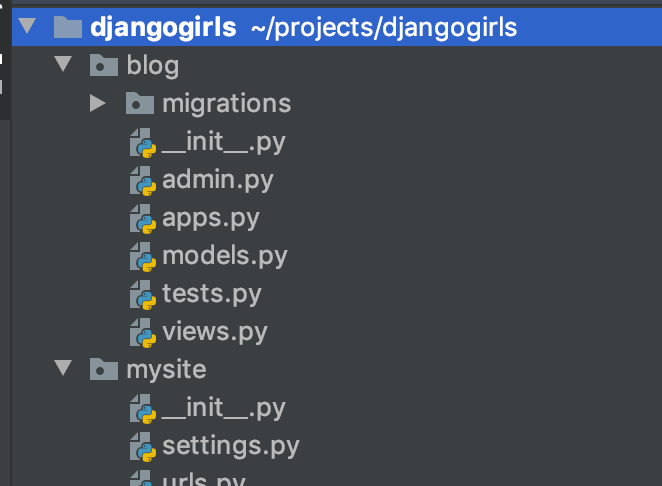
오 프로젝트에 또 다른 패키지가 생겼네요. 이 패키지는
migrations라는 하위 패키지를 가지고 있고,admin.py,apps.py,models.py,test.py,view.py를 가지고 있네요.다른 것들은 찬찬히 살펴보기로 하고, 우리의 목표를 위해 먼저
model.py를 살펴봅시다.Model 클래스 추가하기
블로그에는 포스팅이 있어야겠죠? 지금 제가 쓰고 있는 것 처럼요 ㅎㅎ. 지금
model.py파일을 열어봐도 아무것도 보이지 않습니다. 여기에 모델을 만드세요- 라고만 적혀져 있네요. 이제 Post 라는 Model class를 추가해봅시다.from django.db import models class Post(models.Model): author = models.ForeignKey(settings.AUTH_USER_MODEL, on_delete=models.CASCADE) title = models.CharField(max_length=200) text = models.TextField(blank=True) created_date = models.DateTimeField(default=timezone.now) published_date = models.DateTimeField(blank=True, null=True) def publish(self): self.published_date = timezone.now() self.save() def __str__(self): return self.title네 이렇게 따라서 치시면 아마 빨간줄로 뭐가 없어~~라고 PyCharm이 알려줄거에요.
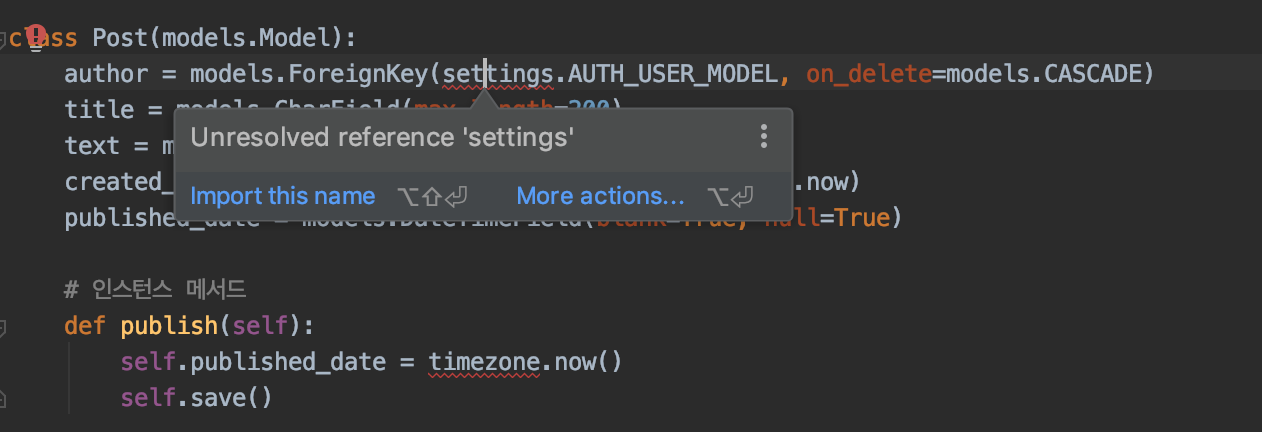
그럼
import this name을 눌러줍시다. (혹은 Alt + Enter) 요렇게 두 번만 하면?from django.conf import settings from django.db import models from django.utils import timezone class Post(models.Model): author = models.ForeignKey(settings.AUTH_USER_MODEL, on_delete=models.CASCADE) title = models.CharField(max_length=200) text = models.TextField(blank=True) created_date = models.DateTimeField(default=timezone.now) published_date = models.DateTimeField(blank=True, null=True) def publish(self): self.published_date = timezone.now() self.save() def __str__(self): return self.title이런식으로 필요한 항목들을 import 할 수 있습니다. 하지만 같은 패키지명을 가지는 경우가 많기 때문에 import 할 때는 주의를 기울여야해요 :)
코드를 잠깐 살펴보죠. 처음 세 줄은 필요한 패키지들을 import 해온 코드입니다.
다음으로
Post라는 클래스를 정의해주었는데요, 특이한 점은Post(models.Model)요 부분입니다. 이렇게 class를 정의하면서django.db의models.Model을 명시해주면 이 클래스를 기반으로 데이터베이스의 Entity가 만들어질 것이다- 라고 알려주게 됩니다.attribute
그럼 이제 이
Post클래스에 어떤 attribute가 포함되는지 정의해줍시다.python에서는 클래스 정의에{ }를 사용하지 않고, tab을 기반으로 정의부인지 아닌지를 구분합니다.Post클래스에는 5개의 attribute가 포함됩니다. 코드를 그대로 읽어볼까요?- author는 settings의
AUTH_USER_MODEL와 연결된 외래키이고, 이 외래키가 삭제될 때CASCADE옵션을 가집니다. 함께 삭제된다는 거죠. - title은 최대 길이가 200인
Character Field입니다. - text는
Text Field이며, 비어있을 수 있습니다. - created_date 는 날짜와 시간을 저장하는
DateTimeField이며, 기본값은 인스턴스가 생성괴는 시점입니다. - published_date 또한
DateTimeField이며, null일 수도, 비어있을 수도 있습니다.
blank vs null
두 가지는 유사하지만 조금 다릅니다. blank는 Application 시점에서 이 값이 필수인지 아닌지를 판단하게 될 때 사용됩니다. null은 Database에서 이 값이 nullable 한지 여부를 나타냅니다.
예를 들어서
published_date의 옵션이blank=True, null=False라면, 사용자가 포스팅을 작성했을 때published_date를 입력하지 않아도 포스팅을 작성할 수 있지만 데이터베이스에서는 null이 허용되지 않기 때문에 자동으로 기본값을 지정해주거나created_date값과 동일하게 가져가는 등의 처리를 해주어야 합니다.method
Postclass에는 총 두 개의 instance method가 정의되어 있습니다. 첫 번째로 포스팅을 발행(publish)하는 메서드, 그리고 인스턴스 클래스를 나타낼 때 사용하는 Description 메서드(일명 매직메서드래요).python에서 정의할 수 있는 method는 instance method/static method/class method의 3 종류가 있는데, 다음에python문법을 살펴보면서 좀 더 자세히 알아봅시다.Database Migration
자 이제 열심히 새로운 Model 클래스를 생성했으니까, 이걸 Database에 적용해봅시다. 이렇게 새로운 변경사항을 Database에 적용하는 걸
migration이라고 부릅니다.아까 Application을 추가한 것처럼, 프로젝트를 관리하는
manage.py에게 Database에 변동사항이 있어! 라고 알려줍시다.$ python manage.py makemigrations blog그럼 다음과 같은 오류문구가 나타납니다.

음????? 아냐 나 blog 앱 만들었는데? 혹시 제가 누락한 것 같으니까 다시 만들어봅시다.

ㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎ 있는데 왜 찾지를 못하니..!!!!!!!
Application을 생성하는 것은 자동으로 해주지만, 모든 Application이 자동으로 프로젝트에 포함되는 것은 아닙니다. 필요에 따라 기존 Application이 빠져야 할 수도 있고, 아직 개발중이라서 못 넣을 수도 있잖아요!
프로젝트에 어떤 Application들이 포함될지는
settings.py에서 결정합니다.settings.py에 ‘blog’라는 이름의 application이 포함될 거라고 적어줍시다. 한 줄을 비운 이유는 기존 django 모듈들과 구분하고자 한 줄을 비워두었습니다.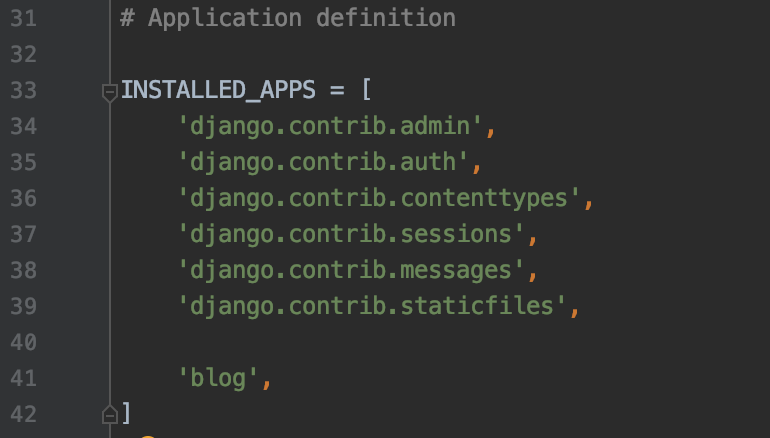
자 이제
blogApplication도 넣었으니 다시 migration 명령어를 입력해봅시다.blog/migrations/0001_initial.py라는 처음 보는 파일 이름에 - Create model Post 를 보여주고 마무리가 됩니다.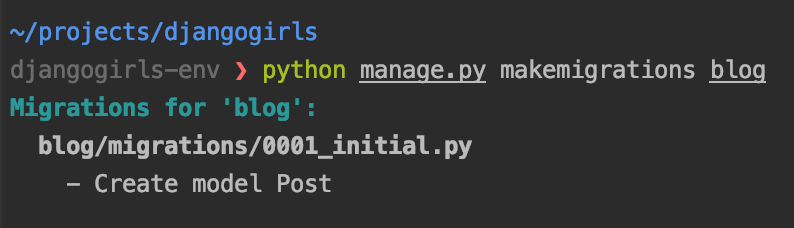
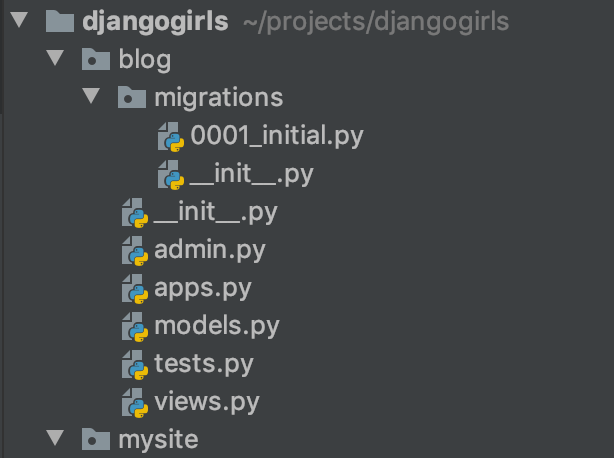
실제로 프로젝트 네비게이터에서 blog/migrations 폴더 하위에 새로운 파일이 생긴 걸 확인할 수 있습니다.
Database Migration 적용하기
migration 파일이 생성되었다고 해서 데이터베이스에 적용되는 것은 아닙니다. migration 파일은 일종의 임시저장 이라고 보면 될 것 같아요. 기존에서 현재까지의 변동사항을 하나의 파일로 저장해둡니다.
이후에 다른 변동사항이 생긴다면, 또 다른 migration 파일을 생성해서 관리할 수 있습니다.
migration 파일을 실제 Database에 적용하려면,
manage.py의 migrate 명령을 사용할 수 있습니다.$ python manage.py migrate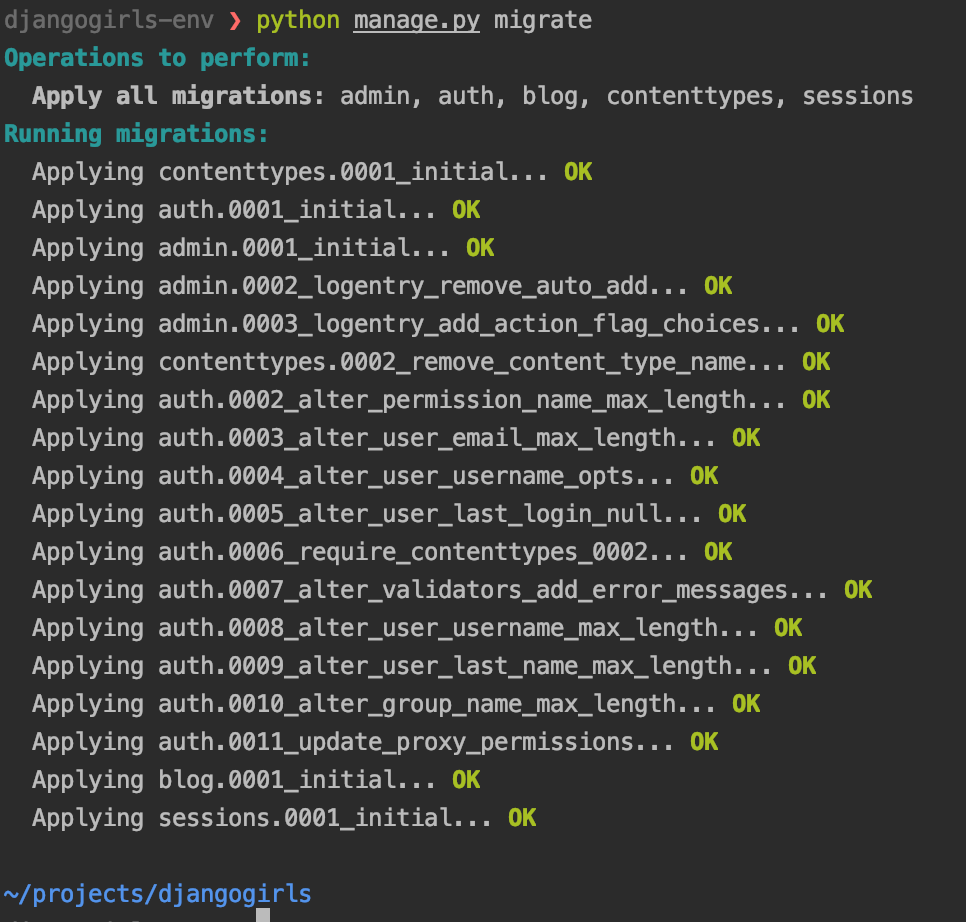
오.. 제가 생성한 migration 파일은 하나지만, 이 프로젝트에서 사용하는 django 기본 application에 필요한 Database migration이 자동으로 진행됩니다.
자 그럼 이제 migration이 끝났는데, 그 결과를 어디가야 볼 수 있을까요?
Database 확인하기
맨 처음 blog application을 생성했을 때, 프로젝트에 뭔가 새로운 파일이 생긴 것을 알아채셨나요?
blog application을 추가하면서 Database 사용을 위해 blog 패키지 하위에 migrations 패키지가 생긴 것처럼, 프로젝트에서도 Database를 사용하기 위해
db.sqlite3파일이 추가되었습니다.Django 프로젝트에서는
.sqlite3를 사용해서 Database를 관리하고, 이 파일을 DB Browser SQLite를 통해 열면 Database 내부의 데이터를 확인할 수 있습니다.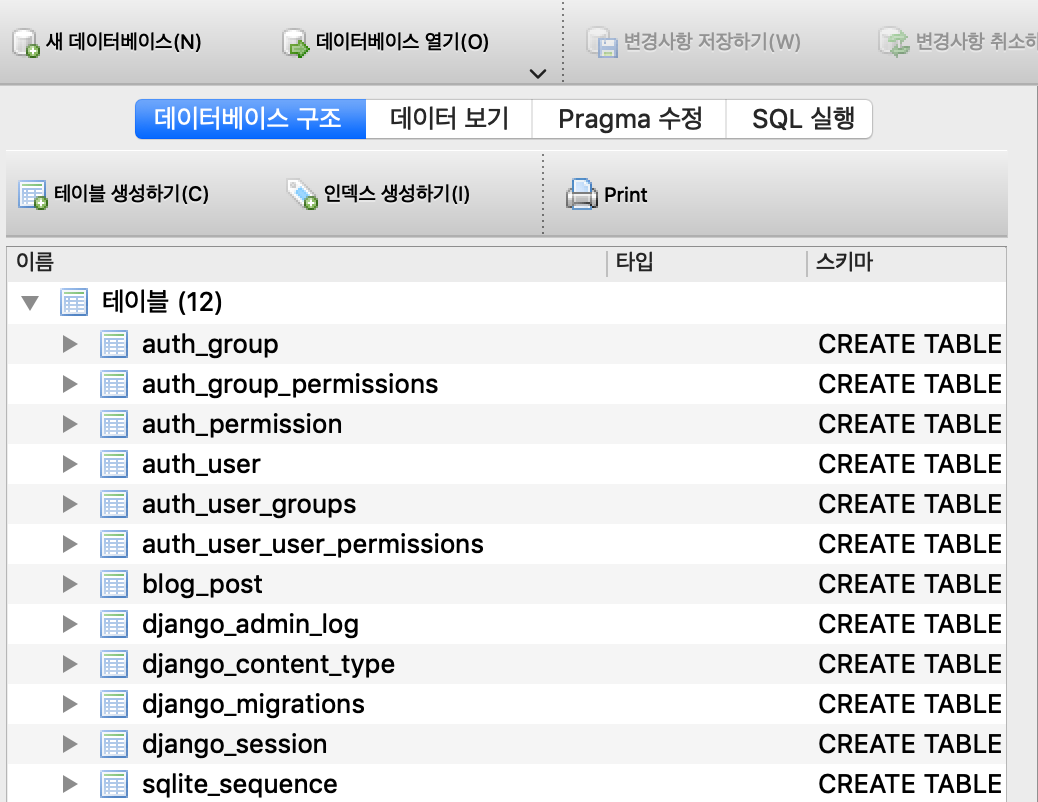
잘 찾아보면 우리가 만들었던
blogapplication의postmodel을 나타내는 테이블을 찾을 수 있을거에요.하지만 이 테이블을 열어봐도 아무런 데이터가 나타나지 않습니다 ㅠ_ㅠ 왜냐면 데이터가 없으니까요! (아무말)
그럼 이제 데이터를 넣을 수 있는 관리자 페이지를 만들어봅시다.
새로운 페이지 추가하기
관리자 페이지를 만들어보기 전에, 우리가 생성한 새로운 페이지를 프로젝트에 추가해봅시다.
URL 추가하기
새로운 페이지를 보여주려면, 그 페이지에 접속할 URL을 만들어야하겠죠? URL의 관리는
mysite/urls.py에서 관리할 수 있습니다.우리는 포스팅 리스트를 볼 수 있는 페이지를 만들거에요. URL은
post-list로 만들어 봅시다.from blog.views import post_list urlpatterns = [ path('admin/', admin.site.urls), path('post-list/', post_list), ]path(,)의 첫 번째 파라미터는 URL을 나타내고, 두 번째 파라미터는 이에 대응하는 실제 view를 나타냅니다. 이 상태에서
urls.py를 저장하면 runserver에서 오류로그가 막 올라옵니다.
빠밤..
post_list라는 걸 찾을 수 없다네요… 역시 인생 쉽지 않아요. ㅜURL은 등록하려면 이 url에 대응되는 view를 반환해주어야하나 봅니다. 그럼 이제 view를 추가하러 갑시다.
View 추가하기
페이지 관리는
views.py에서 관리합니다.급한 불을 끄려면 일단
post_list를 요청할 때 String 문자열이라도 내보내줍시다.def post_list(request): return HttpResponse('Post List!')이 메서드는 request를 받았을 때, 이 request에 대한 응답으로
HttpResponse라는 클래스의 인스턴스를 생성해서 전달해줍니다. 생성자의 파라미터로는 간단하게 ‘Post List!’라고 적어주었습니다.그리고 나서
urls.py로 돌아가서views.py의post_list를 참조할 수 있도록 import 해줍시다. 그리고 나서 저장을 하면~ 정상적으로 서버가 다시 시작됩니다.이제 실제 브라우저에서 http://127.0.0.1:8000/post-list/에 접속해봅시다.

잘 뜨시나요? 오와앙 우리의 첫 번째 페이지를 띄우는 데 성공했습니다.
HTML 파일 보여주기
사실 웹 페이지라고 하면 보통 HTML 파일을 먼저 떠올리기 마련입니다.
사실 급한 불은 껏지만, 우리가 원했던 건 한 줄의 문자열보단 예쁜! 화면을 만들어나가는 거겠죠. 그럼 우리가 알고 있는 html 파일을 보여주려면 어떻게 해야할까요?
먼저 간단한 html 파일을 만들어봅시다. 저는 프로젝트 최상단에서
/templates/post_list.html파일을 생성하고 다음과 같이 써넣었습니다.<!Doctype html> <html lang="ko"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> </head> <body> <h1>post list</h1> </body> </html>이제
post_list를 요청했을 때 이 html 파일이 불러와지도록 만들어봅시다. 그럼 앞서 작성했던post_list(request)메서드를 조금 수정합니다. :)def post_list(request): return render(request, 'post_list.html')render(,)메서드는 request를 받아서 이에 대응되는 HttpResponse 인스턴스를 만들어주는 메서드이며, 두 번째 파라미터로 사용할 resource 파일 이름을 받았습니다. 그러면 프로젝트 내에서post_list.html을 찾아서 랜더링하여 response를 보냅니다.메서드를 수정하고 다시 브라우저 화면을 새로고침해볼까요?
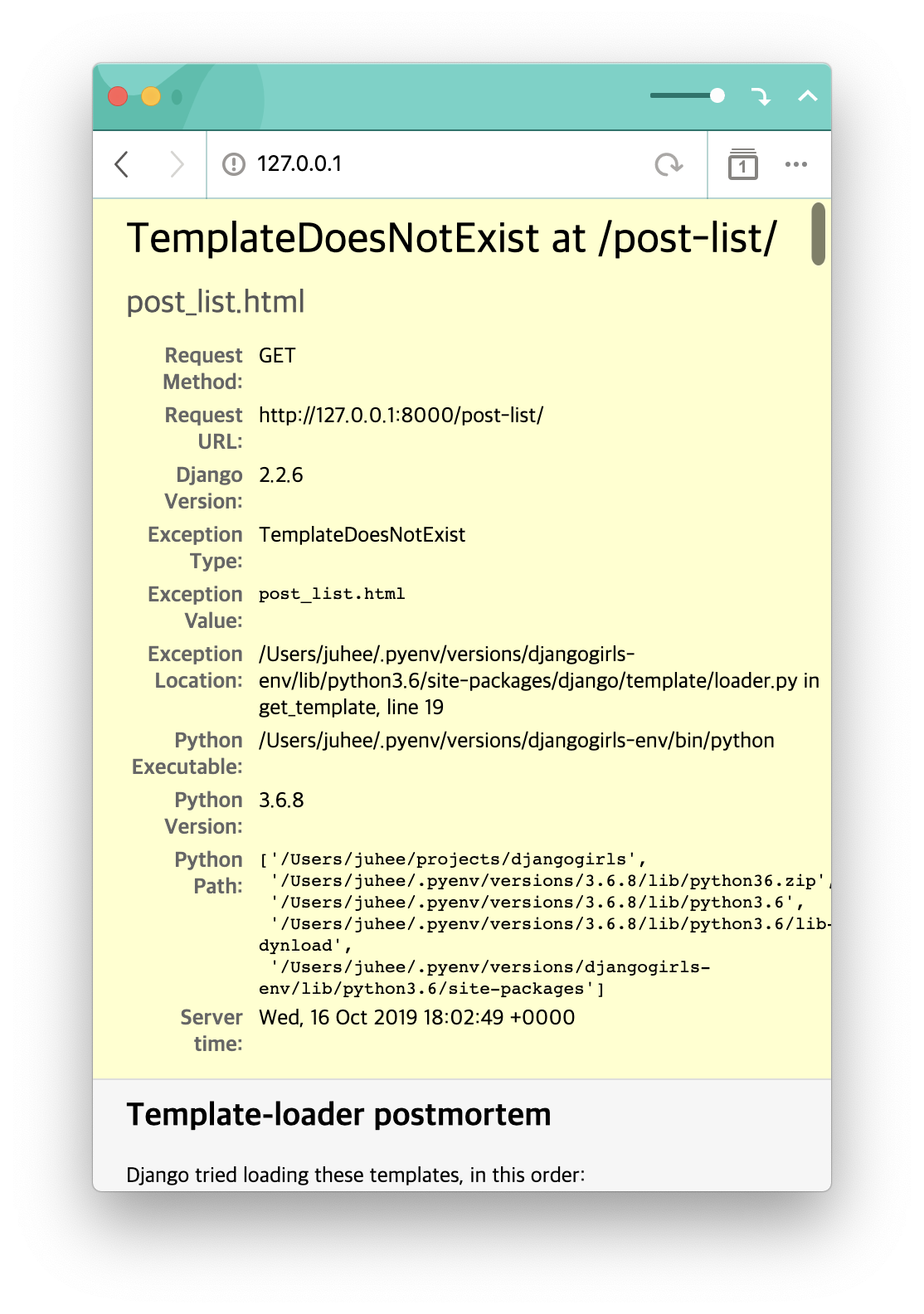
오옷…. 그런 template을 찾을 수 없다는 군요. 마찬가지로 template 또한 settings.py의 TEMPLATES의 DIRS 하위에 path를 명시해주어야 합니다.
TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [ os.path.join(BASE_DIR, 'templates') ], 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', ], }, }, ]다시 한 번 돌려볼까요!
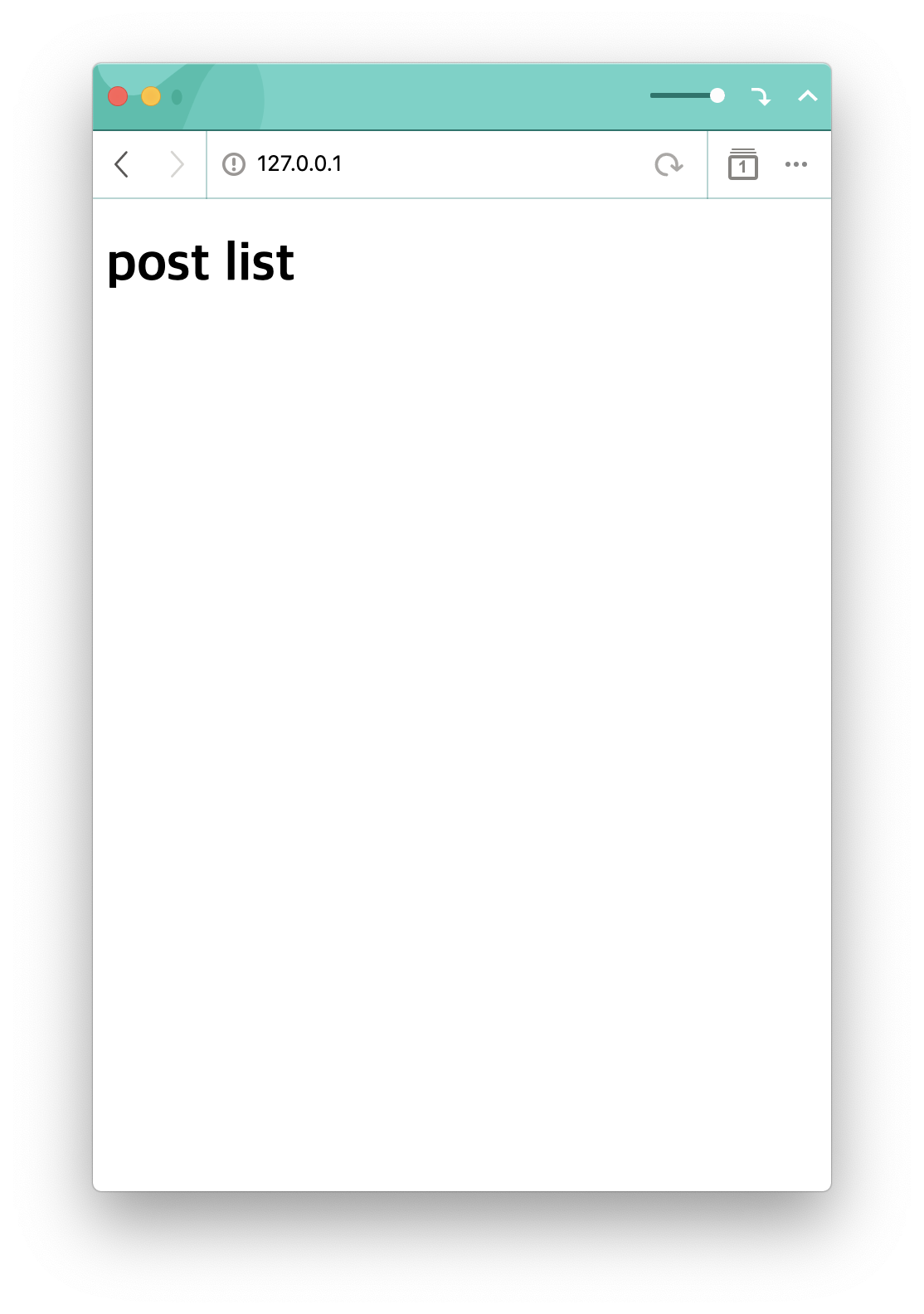
굳굳! 이런 방식으로 원하는 위치의 html 파일을 불러올 수 있습니다. 나중엔 템플릿 파일을 가지고 동적으로 데이터바인딩하는 부분 또한 다뤄볼 수 있겠네요.
관리자 페이지 관리
관리자 페이지 관리라니 저의 라임이 아주 날로 갈 수록 무르익는군요. 하하. 지금 새벽 세시라서 매우 졸려서 그렇습니다. 봐주십쇼. 저희 스터디의 마지막 목표는 바로 포스트 리스트를 볼 수 있는 관리자 페이지를 띄우는 것이었습니다.
그럼 관리자 페이지는 어떻게 만들 수 있을까요? 아까 제가 듣기로는 Django에서 관리자 페이지 만드는 게 참참참 쉽다고 들었는뎁쇼! XD
관리자 페이지 만드는 법! 아주 간단합니다.
admins.py
관리자 페이지는
admins.py에서 관리합니다. 여기에 관리할 model을 적어주기만 하면 됩니다.from django.contrib import admin from .models import Post admin.site.register(Post)오 이게 단가요? 네 이게 답니다. 그럼 이제 admin 페이지에 들어가봅시다.
음…. 저는 아이디와 비밀번호가 없는뎁쇼? 그럼 이제 만들어봅시다 XD
로컬 사용자 만들기
admin 페이지에 접속할 수 있는 local 유저를 생성하는 것 또한
manage.py스크립트를 사용합니다.python manage.py createsuperuser그럼 이제 아이디를 뭘 할 건지, 이메일, 비밀번호, 비밀번호 이거 너무 쉬운데 이거 쓸거니 하고 물어봅니다.
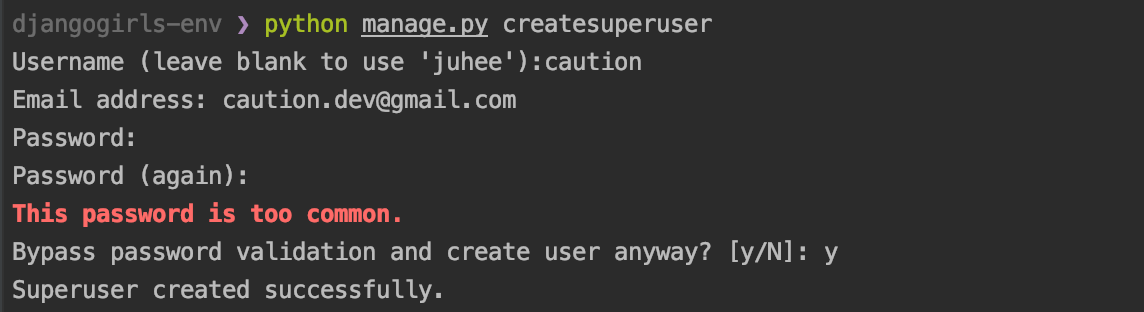
저는 쿨하게 y했구요. 이제 만든 사용자로 로그인을 해봅시다.
혹시 저처럼 비밀번호를 잊어버리신 분이 있다면
python manage.py changepassword를 사용하여 변경할 수 있으니 걱정마세요!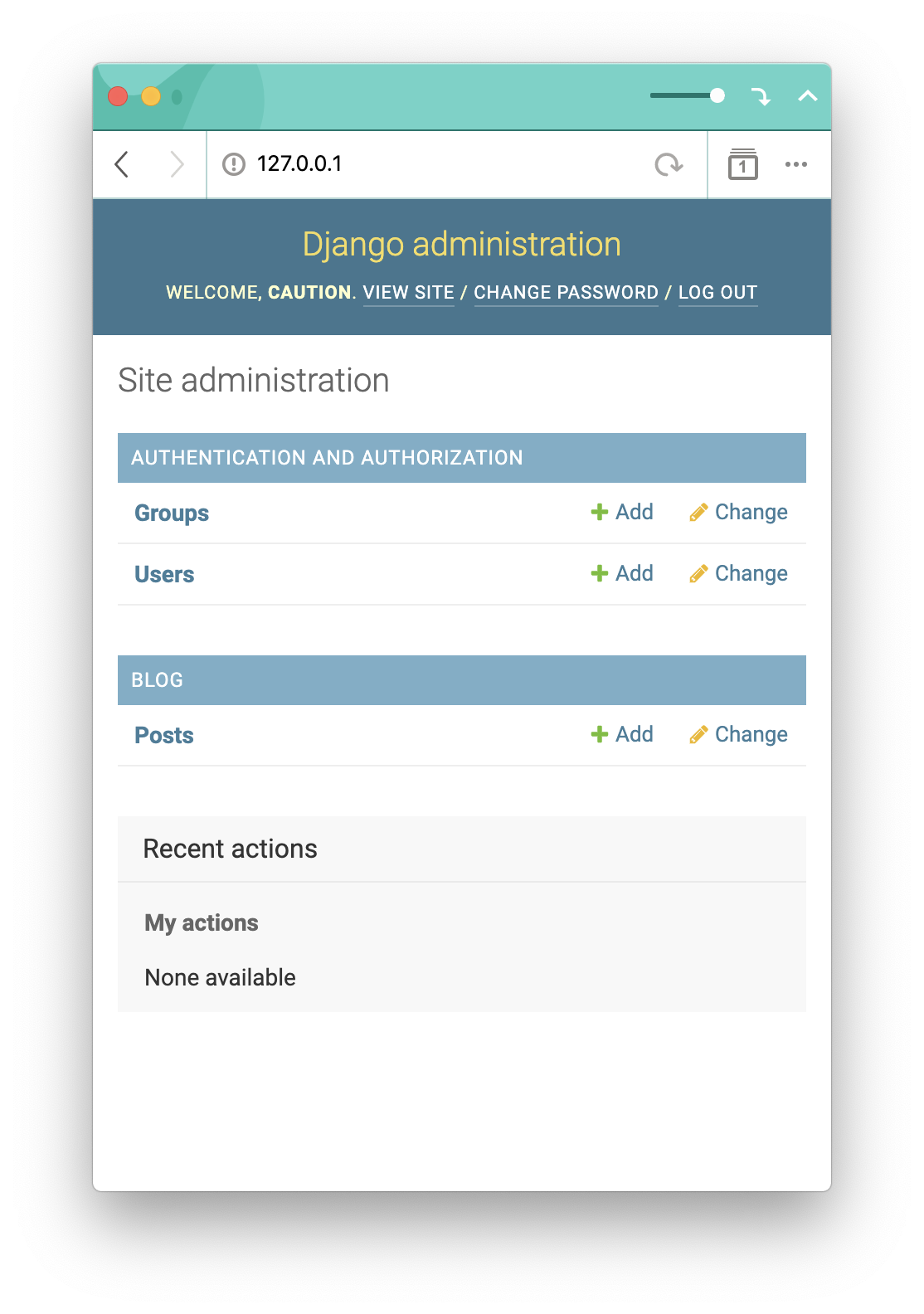
우왕! 관리자 페이지가 열렸네요~ 여기에서 새로운 post 를 작성하고 기존 데이터들도 관리할 수 있습니다.
그리고 변경된 데이터는 DB Browser 에서 확인할 수 있다는 점~~ 잊지마시고용!
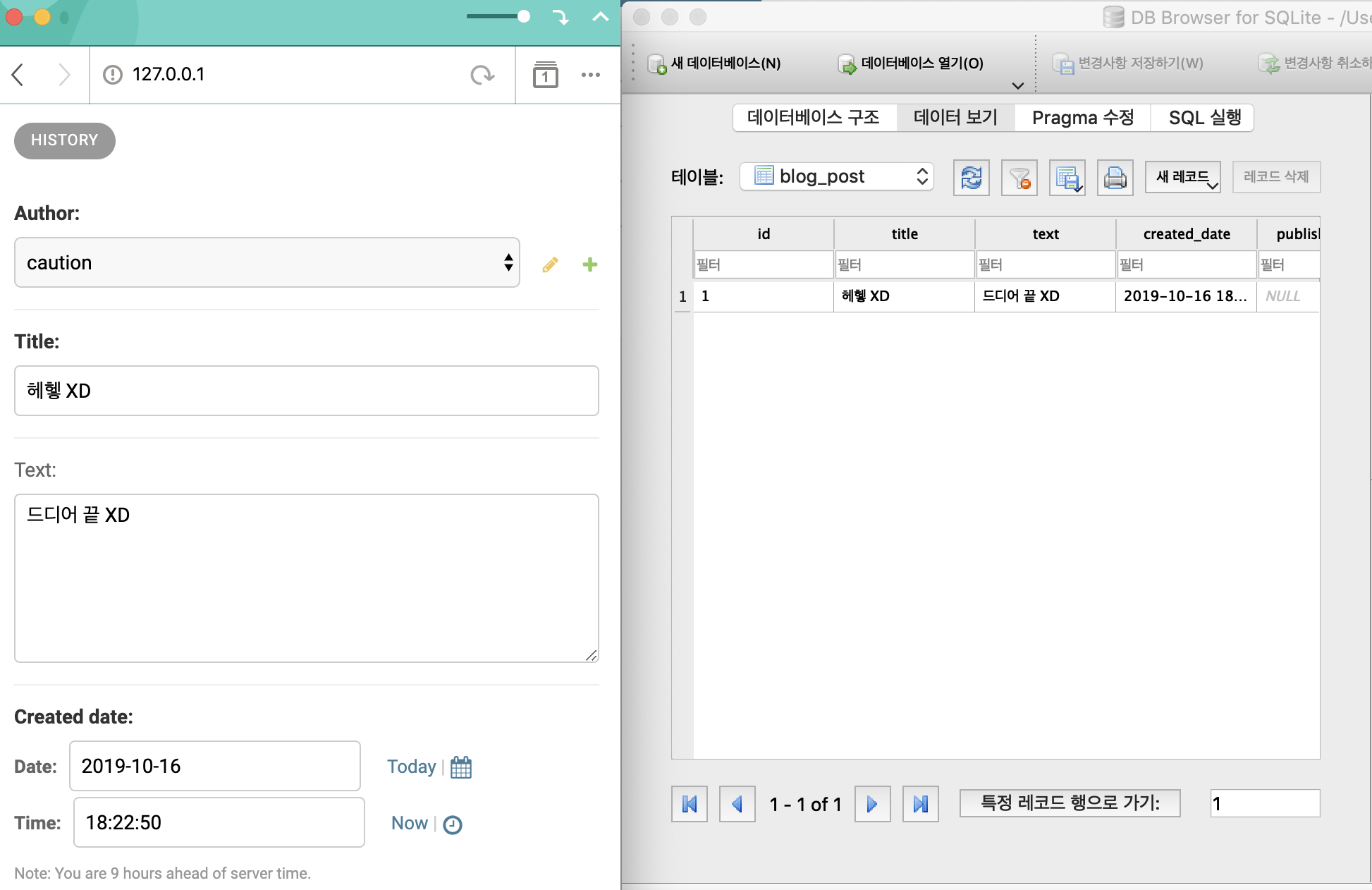
길고 긴 포스팅이 끝났습니다!!!!!!!!!!
다음엔 좀 더 짧은 호흡으로 포스팅 올릴게요 XD
다 쓰고 나니까 세시라서 핵졸려요
구롬 20000!!!!
-
Core Data - Tutorial
안녕하세요! caution 입니다. 현재 Mashup이라는 동아리를 하고 있는데, iOS 팀 세션에서 간단히 Core Data를 익힐 수 있는 발표를 진행했습니다. 그 내용을 정리해서 공유하고자 합니다.
Core Data에 대해 더 세부적인 개념이 필요하다면 이전 포스팅을 찹고해주세요! 그럼, 시작합니다!
CoreData?
CoreData란 무엇인가요?
iOS 앱에서는 데이터를 저장하기 위한 다양한 방식을 제공합니다.
Document영역에 파일을 저장할 수도 있고, 간단한 설정이라면UserDefaults를 사용할 수도 있습니다. 혹은Realm이나SQLite와 같은 Database를 사용할 수도 있죠.CoreData도 마찬가지입니다. CoreData는 앱에서 모델 레이어 객체의 관리에 사용할 수 있는 프레임워크입니다.
CoreData는 이 모델 레이어 객체의 life cycle 관리나, object graph management, 영속성 관리와 관련된 일반적인 해결책들을 제공하고 있습니다.
object graph management 란, 파일 형태로 저장되어 있는 데이터를 지정된 객체와 연결해주는 것을 의미합니다. CoreData를 사용하면 데이터를 읽어왔을 때 그 결과가 객체의 형태를 띄고, 객체의 속성을 수정함으로써 그대로 다시 데이터를 저장할 수 있습니다.
CoreData는 영속성 관리를 위해
SQLite를 사용하지만,SQLite의 wrapper 역할을 하는 것은 아닙니다.- CoreData를 사용하면
Library/Application Support에.sqlite파일이 생성됩니다. 이를 통해 내부에 저장된 데이터를 읽고/수정하는 것이 가능합니다. - 하지만 데이터 영속성을 위해
SQLite를 쓴다고 해서SQLite가 지원하는 모든 동작을 지원하는 것은 아니며, 같은 동작이더라도 내부적으로 다르게 동작할 수 있습니다.
CoreData는 어떻게 구성되어 있나요?
CoreData를 구성하는 다양한 클래스들이 있습니다. 이를 모두 살펴보기는 어렵고, 직접 사용함에 있어서 꼭 필요한 녀석들을 설명하겠습니다.
잠깐 CoreData는 접어두고, 우리의 앱에서 객체 데이터를 파일로 저장한다고 생각해봅시다. 어떤 동작들이 필요할까요?
먼저 우리가 원하는 형태의 class를 생성해야 할 것입니다. 어떤 데이터를 저장하고 싶은 것인지 정해야겠죠.
하지만 우리는 하나가 아닌 여러 class의 데이터를 저장할 것입니다. 그러려면 이 객체들을 관리하고 있는 관리자가 필요하겠네요. 이제부터 이 관리자는 객체들의 생성, 수정을 관리하게 됩니다.
이제 원하는 데이터를 파일에 저장해야 합니다. 나중에 파일에서 다시 데이터를 불러올 수 있도록하는 기능도 구현해야 할 것입니다. 파일로 저장하는 동작은 실패할 수도 있고, 성공할 수도 있습니다.
크게 이렇게 세 가지 동작으로 나눌 수 있겠습니다. 이걸 CoreData와 연관지어서 생각해보죠. 차근차근히요.
.xcdatamodeld
프로젝트를 처음 생성할 때
Use Core Data를 선택하면 자동으로 이 확장자를 가진 파일이 생성됩니다. 이 파일에서는 Core Data로 저장할Entity,Fetched Request들을 정의하고 그 관계를 구상할 수 있습니다.다음과 같이 어떤 Entity에 어떤 Type의 Attribute가 있는지 정의할 수 있습니다.
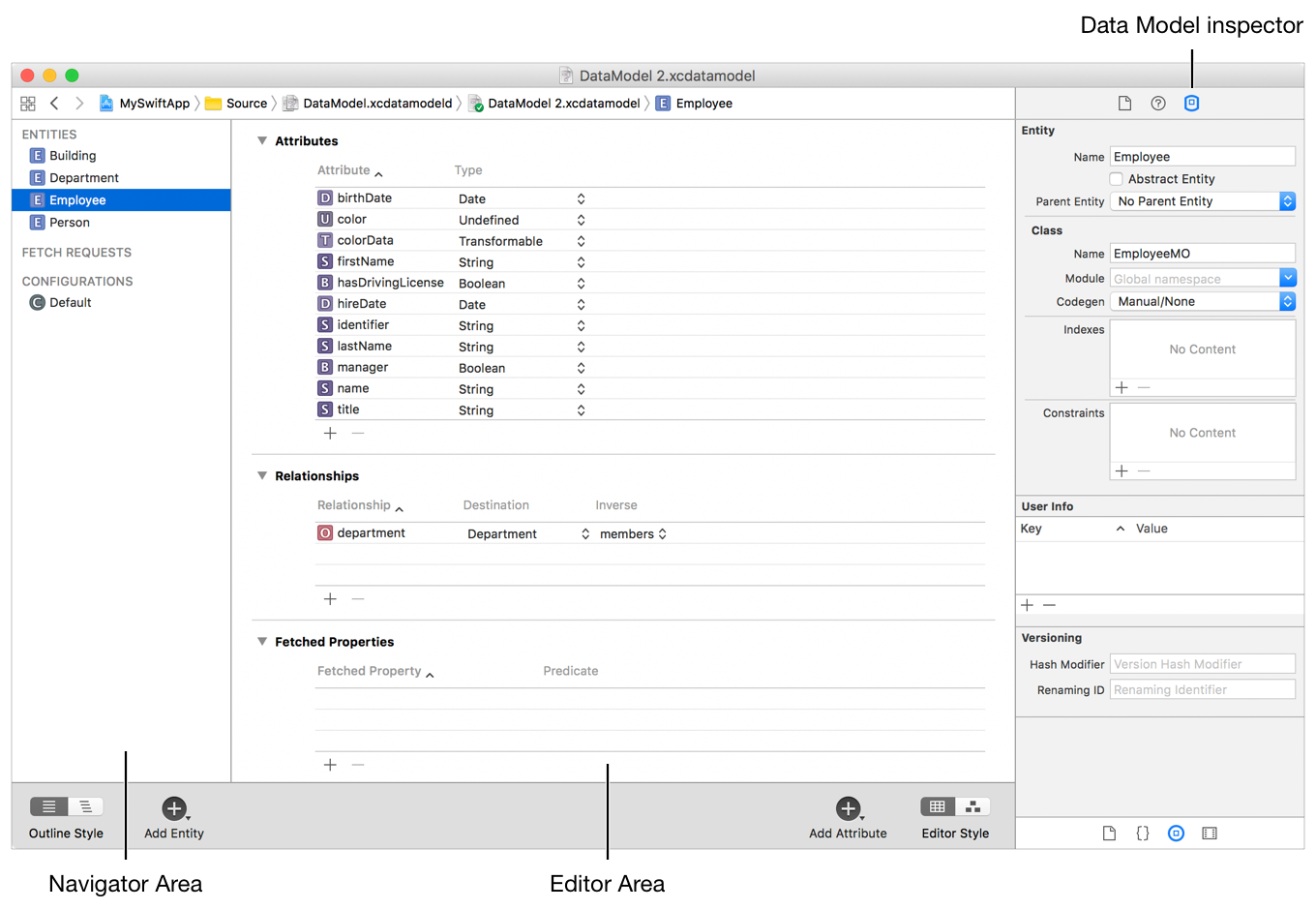
또한 Entity들간의 Relationship 을 정의할 수 있으며, 추상 Entity도 만들 수 있습니다.
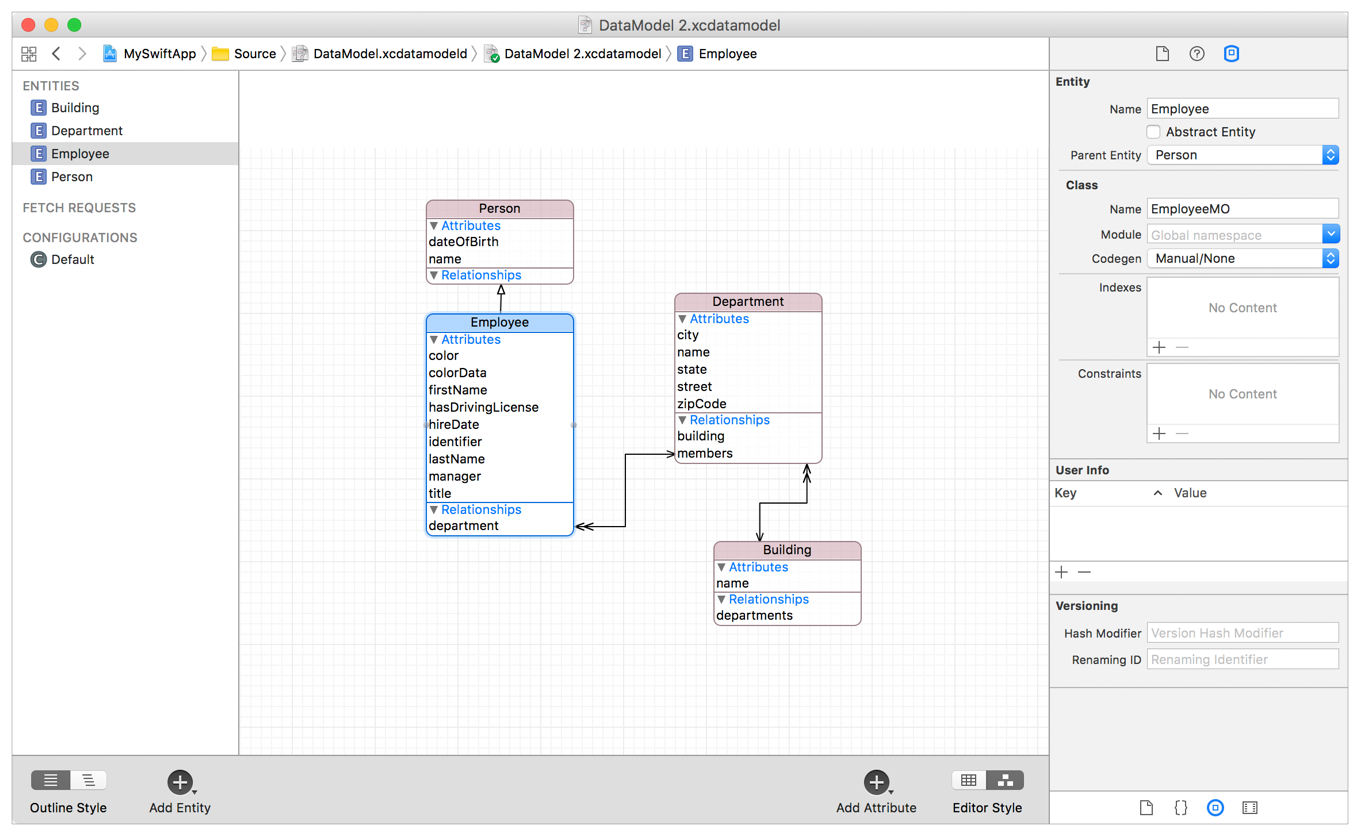
이미지 출처 : Apple-Core-Data
이제 어떤 데이터들을 저장할 지, 그리고 Entity간 관계가 정해졌다면, 실제로 이 데이터들이 어떤 객체로 연결될 것인지를 설정해주어야 합니다.
NSManagedObjectModel
NSPersistentStoreCoordinator가 데이터를 읽어서NSManagedObjectContext로 올릴 때.xcdatamodeld파일로부터NSManagedObjectModel객체를 만듭니다. 이 객체는 스키마의 Entity를 나타내는 하나 이상의NSEntityDescription객체가 포함되어 있습니다. 각NSEntityDescription객체에는 스키마의 Entity attribute (or field)을 나타내는 속성 설명 개체 (NSPropertyDescription의 하위 클래스 인스턴스)가 있습니다.즉
NSPersistentStoreCoordinator는NSManagedObjectModel을 사용하여NSManagedObjectContext에 올라가 있는NSManagedObject인스턴스들의 데이터를 File에 저장할 수 있는 형태로 변환하고, File에서 읽어들일 때 다시NSManagedObject로 변환해야 할 때 이NSManagedObjectModel에 기반하여 변환합니다.NSManagedObject
NSManagedObject는NSPersistentStoreCoordinator에 의해서 인스턴스화 된 Entity의 데이터(Record)를 나타냅니다. 모든NSManagedObject는NSManagedObjectContext에 의해 관리됩니다.NSManagedObject인스턴스를 통해 앱의 데이터를 추가/수정/삭제할 것입니다. 그러므로 각 Entity에 대응되는NSManagedObject가 필요합니다.import UIKit import CoreData import Foundation class EmployeeMO: NSManagedObject { @NSManaged var name: String? }이
NSManagedObjectclass는 직접 정의할 수도 있지만, 일반적으로는.xcdatamodeld을 통해 Entity 구조를 만들고 이를 기반으로NSManagedObjectclass들을 generate 합니다. 이 방법은 Xcode에서 기본적으로 지원하며, 자세한 사항은 Tutorial project를 진행하면서 설명하겠습니다.여기까지가 Core Data에서 Entity 구조를 구성하는 파일과, 이에 연결될 수 있는 객체를 살펴보았습니다. 실제로는
NSManagedObject파일을 우리가 다루는 일반적인 model struct/class 처럼 사용하게 될 것이며,NSManagedObjectModel을 직접 다루지는 않을 것입니다.NSManagedObjectContext
앞서 잠깐 설명드리면서 언급되었던 class 입니다. 이 클래스는
NSManagedObject인스턴스들을 생성하고, 관리하는 역할을 합니다. 파일에서 불러와진 데이터들을 기반으로NSManagedObject인스턴스로 변환하면NSManagedObjectContext가 관리합니다. 또한 새로운NSManagedObject를 만들려면NSManagedObjectContext를 통해서 생성해야 합니다.func object(with: NSManagedObjectID) -> NSManagedObject // Returns an object for a specified ID even if the object needs to be fetched.그 외에
NSManagedObject가 존재하는지, 그 수를 세거나, 특정NSManagedObject들을 불러올 수 있는NSFetchRequest<NSFetchRequestResult>를 생성하는 등 다양한 메소드들을 제공합니다.NSManagedObject는 Core Data를 사용하면서 가장 자주 사용하게 될 class입니다. 이 클래스는 로드한 Entity의 데이터(Record)들을 관리하고 있으며, Entity에 데이터를 추가하거나, 삭제할 때에도 이 class 인스턴스를 통해야 합니다. 또한 변경된 데이터를 저장할 때에도 이 인스턴스를 사용합니다.주의하세요! Core Data는 in-memory-DB의 역할을 수행합니다. 모든 로드된 데이터는
NSManagedObject가 살아있는 한 memory 위에 올라가 있습니다. 또한, 새로운 데이터가 추가되었든, 수정사항이 발생했든 모든 데이터는NSManagedObject가 가지고 있으며, 명시적으로context.save()를 호출해야 수정사항이 저장됩니다.NSPersistentStoreCoordinator
model을 사용해서
context과persistentStore간의 커뮤니케이션을 도와주는 코디네이터입니다.NSPersistentContainer
NSPersistentContainer는 Core Data에서 정보를 저장하고, 검색하는 것을 용이케 하는 개체들의 집합입니다. 이 개체들의 집합을 Core Data Stack이라고 부릅니다. 즉NSPersistentContainer는 애플리케이션의 Core Data Stack을 캡슐화 한 것입니다. Core Data Stack에는 관리받는 모델(NSManagedObjectModel), 영속성 코디네이터(NSPersistentStoreCoordinator), 관리 객체 컨텍스트(NSManagedObjectContext)를 포함합니다.즉 Core Data Stack이란, CoreData를 이용해서 Model layer를 관리하는 객체들을 아우러 말합니다.
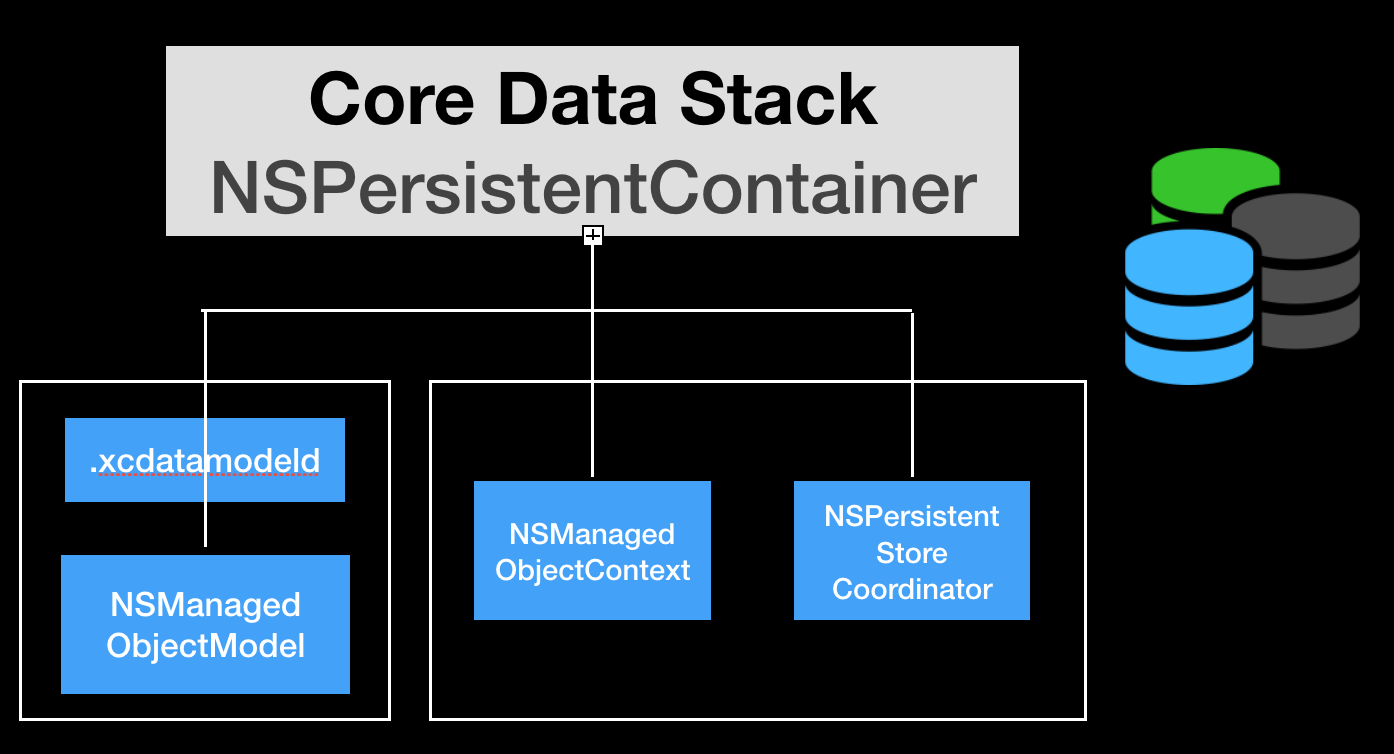
와 이론은 여기까지 입니다 :)
다음 스텝에서는 이제 코드를 기반으로 간단한 메모 앱을 만들어보겠습니다 :)
- CoreData를 사용하면
-
What is Core Data
Core Data란 무엇인가요?
Core Data는 응용 프로그램에서 모델 계층 객체를 관리하는 데 사용하는 프레임 워크입니다. 영속성을 포함하여 객체의 life cycle 등의 기능을 가진 객체 그래프 관리자의 역할을 수행합니다.
코어 데이터는 일반적으로 모델 계층을 지원하기 위해 작성하는 코드의 양을 50-70% 감소시킵니다. 다음과 같은 기본 기능이 제공되기 때문에 구현, 테스트, 최적화 부분을 많이 줄일 수 있습니다.
- 수정사항 트랙킹, 실행취소/재시 도를 기본적으로 제공합니다.
- 객체간 관계를 일관적으로 관리하면서 변경사항을 전파합니다.
- 오버헤드를 줄이기 위해 객체의 지연로딩(Lazy loading), 부분 오류 발생, copy-on-write 데이터 공유를 제공합니다.
- 자동적으로 속성 값의 유효성을 검사합니다. 관리 객체는 표준 key-value 코딩 유효성 검사 메서드들을 확장하여 값이 허용되는 범위 내에 있음을 보장합니다.
- 간단한 스키마 변경이 가능하고 효율적으로 스키마 마이그레이션을 수행할 수 있는 스키마 마이그레이션 도구를 제공합니다.
- 사용자 인터페이스 동기화를 지원하기 위해 응용 프로그램의 컨트롤러 레이어와 선택적으로 통합할 수 있습니다.
- 메모리 및 사용자 인터페이스에서 데이터를 그룹화하고 필터링, 조직화할 수 있습니다.
- 외부 데이터 저장소에 객체들을 저장하도록 지원합니다.
- 정교한 쿼리 컴파일. SQL을 작성하는 대신 NSPredicate 오브젝트를 fetch request과 연관시켜 복잡한 쿼리를 작성할 수 있습니다.
- 자동 충돌 해결을 지원하기 위해 버전 추적과 최적화 locking을 제공합니다.
- macOS 및 iOS 툴 체인과의 효과적인 통합.
Core Data는 영구저장을 위해 SQLite 를 사용합니다.
- SQLite 및 일반적인 DBMS 에서 지원하는 검색, 정렬 등의 기능을 제공합니다.
- SQLite의 Wrapper가 아닙니다. 동일한 기능을 제공한다 하더라도 SQLite 와 다른 로직으로 수행될 수 있습니다.
- 또한 SQLite에서 제공하는 모든 기능을 제공하는 것이 아닙니다. (예: 자동 데이터 증가 attribute)
- SQLite는 영속성 유지를 위해 디스크에 데이터를 저장하지만, Core Data는 완전한 인-메모리 형태로 사용 가능합니다. 역설하자면 Core Data는 명시적으로 저장 명령을 내릴때까지 디스크에 저장하지 않습니다.
이 문서는 편의와 명확성을 위해 직원 데이터베이스 스타일의 예제를 사용합니다. 풍부하지만 쉽게 이해할 수있는 문제 영역을 표여줍니다. 그러나 핵심 데이터 프레임 워크는 데이터베이스 스타일의 응용 프로그램이나 클라이언트 - 서버 동작에만 국한되지 않습니다. 이 프레임 워크는 Sketch와 같은 벡터 그래픽 응용 프로그램이나 Keynote와 같은 프레젠테이션 응용 프로그램의 기초만큼 유용합니다.
Data Model 만들기
Core Data의 기능 대부분은 응용 프로그램의 엔터티, 속성 및 속성 간의 관계를 설명하기 위해 만드는 스키마에 따라 달라집니다. 핵심 데이터는 NSManagedObjectModel의 인스턴스인 관리 객체 모델이라 불리는 스키마를 사용합니다. 일반적으로 모델이 풍부할수록 더 우수한 Core Data가 응용 프로그램을 지원할 수 있습니다.
Entity와 그 Property 만들기
Xcode에서 새 프로젝트를 시작하고 템플릿 선택 대화 상자를 열 때 코어 데이터 사용 확인란을 선택합니다. 코어 데이터 모델의 소스 파일이 템플리트의 일부로 작성됩니다. 해당 소스 파일의 확장자는 .xcdatamodeld입니다. 탐색기 영역에서 해당 파일을 선택하여 핵심 데이터 모델 편집기를 표시하십시오.
-
Share
여러 관찰자가 하나의 구독에서만 이벤트를 공유하기 원하면 어떻게 해야 할까요?
정의해야 할 2가지가 있습니다.
- 새로운 구독자가 관찰을 시작하기 전에 수신된 과거의 이벤트를 처리할 것인가?
- 최신것만 반복, 전체를 반복, 마지막 n개만 반복
- 공유 구독을 시작할 시기는 언제인가?
- refCount, 수동, 혹은 기타 알고리즘
보통은
replay(1).refCount()을 조합한share(replay:1)을 사용합니다.let counter = myInterval(.milliseconds(100)) .share(replay: 1) print("Started ----") let subscription1 = counter .subscribe(onNext: { n in print("First \(n)") }) let subscription2 = counter .subscribe(onNext: { n in print("Second \(n)") }) Thread.sleep(forTimeInterval: 0.5) subscription1.dispose() Thread.sleep(forTimeInterval: 0.5) subscription2.dispose() print("Ended ----")결과는 다음과 같습니다.
Started ---- Subscribed First 0 Second 0 First 1 Second 1 First 2 Second 2 First 3 Second 3 First 4 Second 4 First 5 Second 5 Second 6 Second 7 Second 8 Second 9 Disposed Ended ----Subscribed와Disposed이벤트가 한번씩만 발생하는 것을 볼 수 있습니다.URL observable을 위해서도 똑같이 동작합니다.
다음은 Rx로 HTTP Request를 보내는 방법입니다.
interval연산자의 패턴과 비슷해보이네요.extension Reactive where Base: URLSession { public func response(request: URLRequest) -> Observable<(response: HTTPURLResponse, data: Data)> { return Observable.create { observer in let task = self.base.dataTask(with: request) { (data, response, error) in guard let response = response, let data = data else { observer.on(.error(error ?? RxCocoaURLError.unknown)) return } guard let httpResponse = response as? HTTPURLResponse else { observer.on(.error(RxCocoaURLError.nonHTTPResponse(response: response))) return } observer.on(.next((httpResponse, data))) observer.on(.completed) } task.resume() return Disposables.create { task.cancel() } } } }
- 새로운 구독자가 관찰을 시작하기 전에 수신된 과거의 이벤트를 처리할 것인가?
-
RxCocoa - Traits
Driver
이것은 가장 정교한 Trait입니다. 그 의도는 UI 레이어에 반응 코드를 작성하는 직관적인 방법을 제공하거나 응용 프로그램을 구동하는 데이터 스트림을 모델링하려는 모든 경우를 위한 것입니다.
- 오류가 발생하지 않습니다.
- 관찰은 메인 스케줄러에서 발생합니다.
- 부작용을 공유합니다 (
share (replay : 1, scope : .whileConnected)).
이름이 왜 Driver인가?
앱을 구동하는 시퀀스를 모델링하는 데에 그 의도가 있기 때문입니다.
예 :
- CoreData 모델에서 UI를 구동할 때
- 다른 UI 요소의 값을 사용하여 UI를 구동해야할 때.
정상적인 운영 체제 드라이버와 마찬가지로, 시퀀스 오류가 발생하면 응용 프로그램이 사용자 입력에 응답하지 않습니다.
UI 요소와 응용 프로그램 논리가 일반적으로 스레드로부터 안전하지 않기 때문에 이러한 요소들은
main thread에서 관찰되는 것이 매우 중요합니다.또한
Driver는 side effect를 공유하는 observable sequence를 만듭니다.부분 사용 예제
일반적인 beginner 예제입니다!
let results = query.rx.text .throttle(.milliseconds(300), scheduler: MainScheduler.instance) .flatMapLatest { query in fetchAutoCompleteItems(query) } results .map { "\($0.count)" } .bind(to: resultCount.rx.text) .disposed(by: disposeBag) results .bind(to: resultsTableView.rx.items(cellIdentifier: "Cell")) { (_, result, cell) in cell.textLabel?.text = "\(result)" } .disposed(by: disposeBag)위 코드의 의도된 바는 다음과 같습니다.:
- 사용자의 입력을 줄입니다.
- 서버에 접속하여 사용자 결과 목록을 가져옵니다.
- 결과를 두 개의 UI요소 (result table, result count label) 에 바인딩합니다.
그렇다면 이 코드의 문제점은 무엇일까요?
fetchAutoCompleteItemsObservable Sequence 오류가 발생하면 이 오류로 인해 모든 항목의 바인딩이 해제되고 UI가 더 이상 새로운 처리에 응답하지 않습니다.fetchAutoCompleteItems가 일부 백그라운드 스레드에서 결과를 반환할 경우 background thread에서 UI 요소에 바인딩을 시도하기 때문에 크래시가 발생할 수 있습니다.- 결과는 두 개의 UI요소에 바인딩됩니다. 즉, 각 사용자 쿼리에 따른 두 개의 HTTP 요청이 만들어지면서, 결국 다른 결과가 UI에 결과로 들어가기 때문에 의도된 동작이 아닙니다.
위의 코드보다 적절한 버전은 다음과 같습니다.
let results = query.rx.text .throttle(.milliseconds(300), scheduler: MainScheduler.instance) .flatMapLatest { query in fetchAutoCompleteItems(query) .observeOn(MainScheduler.instance) // 결과는 MainScheduler에 의해 반환됩니다. .catchErrorJustReturn([]) // 에러가 발생될 경우 그냥 빈 결과를 반환합니다. } .share(replay: 1) // HTTP requests는 모든 UI element에 반복된 결과가 공유됩니다. results .map { "\($0.count)" } .bind(to: resultCount.rx.text) .disposed(by: disposeBag) results .bind(to: resultsTableView.rx.items(cellIdentifier: "Cell")) { (_, result, cell) in cell.textLabel?.text = "\(result)" } .disposed(by: disposeBag)이러한 모든 요구 사항이 대형 시스템에서 제대로 처리되는지 확인하는 것은 어려울 수 있지만, 컴파일러와 Trait을 사용하여 이러한 요구사항이 충족되었음을 입증하는 간단한 방법이 있습니다.
다음 코드는 위의 코드와 거의 유사해보입니다:
let results = query.rx.text.asDriver() // 일반적인 sequence를 `Driver` sequence로 변환합니다. .throttle(.milliseconds(300), scheduler: MainScheduler.instance) .flatMapLatest { query in fetchAutoCompleteItems(query) .asDriver(onErrorJustReturn: []) // Builder는 오류시에 어떤 걸 반환해야 하는지 만 알면 됩니다. } results .map { "\($0.count)" } .drive(resultCount.rx.text) // 만약 `bind(to:)` 메서드 대신 `drive` 메소드를 사용할 수 있다면, 그것은 모든 프로퍼티가 만족했다는 것을 의미합니다. .disposed(by: disposeBag) // that means that the compiler has proven that all properties // are satisfied. results .drive(resultsTableView.rx.items(cellIdentifier: "Cell")) { (_, result, cell) in cell.textLabel?.text = "\(result)" } .disposed(by: disposeBag)자 무슨 일이 일어난 걸까요?
이 첫 번째
asDriver메서드는ControlProperty특성을Driver로 변경합니다.query.rx.text.asDriver()그 외에 할 필요가 있는 특별한 것이 없단 걸 기억하세요.
Driver에는ControlProperty특성의 모든 특성을 포함하며 더 많은 특성을 가지고 있습니다. 근본적으로는 Observable sequence인데, 이것이Driver로 감싸져있을 뿐입니다.두 번째 변화는 다음과 같습니다:
.asDriver(onErrorJustReturn: [])어느 observable sequence든 다음 3가지 항목을 만족하면
Driver로 변환할 수 있습니다.- error가 발생하지 않습니다.
- main scheduler에서 관찰됩니다.
- side effect를 공유합니다.
그래서 이 프로퍼티들이 만족했는지 어떻게 알 수 있을까요? 일반적인 rx 연산자를 사용해봅시다.
asDriver(onErrorJustReturn:[])는 다음 코드와 같습니다.let safeSequence = xs .observeOn(MainScheduler.instance) // 이벤트들을 main scheduler에서 관찰합니다. .catchErrorJustReturn(onErrorJustReturn) // 에러가 발생하지 않습니다. .share(replay: 1, scope: .whileConnected) // side effect를 공유합니다. return Driver(raw: safeSequence) // Driver로 감쌉니다.마지막은
bind(to:)대신drive를 사용하는 것입니다.drive는Drivertrait에만 정의되어 있습니다. 이는 만약drive를 어디선가 봤다면, 그 observable sequence는 영원히 오류를 발생시키지 않고, 메인 스레드에서 관찰되며, UI 요소에 binding 하는 것이 안전합니다.하지만, 이론적으로 다른 사람이 다른 interface에서
drive메소드를 ObservableType에서 동작하도록 정의했을 수도 있습니다. 그래서 더 안전하게 쓰려면, UI 요소들에 바인딩 하기 전에let results: Driver<[Results]> = ...이런식으로 미리 임시 정의를 만들어 놓아야 완전합니다. 하지만, 이러한 시나리오가 현실적인지 아닌지에 대해서는 독자들에게 남겨두겠습니다.Signal
Signal은Driver와 비슷하지만 한 가지 다른 점이 있는데요, 구독에서 마지막 이벤트를 재사용하지 않지만, 구독자들은 여전히 sequence의 계산된 리소스를 공유합니다.Signal이란:- 에러가 나지 않습니다.
- Main Scheduler에서 이벤트가 발생합니다.
- 계산된 리소스를 공유합니다.
share(scope:: .whileConnected - 구독에서 항목을 replay 하지 않습니다.
-
Why use Rx?
Rx는
Observable<Element>인터페이스를 통해 표현하는 방식으로 Generic 연산을 추상화한 것입니다. (알듯 말듯)여러 언어로 Rx가 구현되어 있으며, RxSwift는 Swift 버전입니다.
원본 버전의 가능한 많은 컨셉을 적용하려고 하고 있지만, iOS/ macOS 환경에 더 적합하고 효율적으로 통합할 수 있도록 몇몇 다른 컨셉들이 채택되었습니다.
여러 플랫폼에 대한 공통적인 문서는 ReactiveX.io에서 찾아볼 수 있습니다.
원본 Rx처럼, 비동기 작업과 event/data stream을 쉽게 구성할 수 있습니다.
KVO observing과 비동기 작업들, 그리고 stream은 모두 시퀀스의 추상화 아래에 통합됩니다. 이는 왜 Rx가 단순하고 우아하고 강력한지를 말해줍니다.
왜 Rx를 사용하나요?
Rx는 선언적 방식으로 앱을 구성할 수 있도록 합니다. (이게 무슨 말이야)
Bindings
Observable.combineLatest(firstName.rx.text, lastname.rx.text) { $0 + " " + $1 } .map { "Greetings, \($0)" } .bind(to: greetingLabel.rx.text)결과
// [(firstName: Heeya, lastName: Kim), (firstName: Juhee, lastName: Kim)] // Greetings, Heeya Kim // Greetings, Juhee Kim // 각 결과가 greetingLabel의 text로 들어갑니다. (rx는 마법의 단어인가??? 싱기)이는
UITableView와UICollectionView와도 함께 동작합니다.viewModel .rows .bind(to: resultsTableView.rx.items(cellIdentifier: "WikipediaSearchCell", cellType: WikipediaSearchCell.self)) { (_, viewModel, cell) in cell.title = viewModel.title cell.url = viewModel.url } .disposed(by: disposeBag)단순한 바인딩이라서 불필요하게 느껴지더라도 항상
.disposed(by: disposeBag)을 사용하길 권장합니다.Retries
만일 API가 실패하지 않는 것이 좋겠지만, 불행히도 실패하죠 하핳. 다음과 같은 API 메서드가 있다고 칩시다.
func doSomethingIncredible(forWho: String) throws -> IncredibleThing만약 기존처럼 이 함수를 사용한다면, 실패의 경우에 이 동작을 다시 시도하는 것이 매우 어렵습니다. exponential backoffs 모델링의 어려움을 언급하지는 않겠습니다. 가능하긴 하지만, 코드에 신경쓰지 않는 일시적인 상태들이 많이 포함될 것이며, 재사용되지 않을 것입니다.
이상적으로 재시도의 본질을 포착하고 모든 작업에 적용할 수 있어야 합니다.
Rx를 사용하면 다음처럼 간편하게 재시도할 수 있습니다 XD
doSomethingIncredible("me") .retry(3)또한 손쉽게 사용자 retry 작업을 만들 수 있습니다.
Delegates
Rx를 사용하면 지루하고 비표현적인 방식을 대체할 수 있습니다.
public func scrollViewDidScroll(scrollView: UIScrollView) { [weak self] // what scroll view is this bound to? self?.leftPositionConstraint.constant = scrollView.contentOffset.x }이렇게요!
self.resultsTableView .rx.contentOffset .map { $0.x } .bind(to: self.leftPositionConstraint.rx.constant) // 아니 근데 기존에 내가 알고 있는 걸 너무 많이 대체하는 것 같다 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ // ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ // 뭔가 돌아올 수 없는 강을 건너는 기분이야 // 하지만 Rx는 짱이겠지 // resultsTableView의 contentOffset이 변경되면 이 Event에 대한 처리를 하는 것 같은데 // contentOffset의 x 값을 받아와서 leftPositionConstraint의 constant 를 업데이트해준당.KVO
기존의 KVO 방식에서는 다음과 같은 오류문구를 접할 수 있습니다.
-(void)observeValueForKeyPath:(NSString *)keyPath ofObject:(id)object change:(NSDictionary *)change context:(void *)context`TickTock` was deallocated while key value observers were still registered with it. Observation info was leaked, and may even become mistakenly attached to some other object.TickTock이 KVO가 등록되어 있는 상태에서dealloc되었습니다. Observation 정보가 누수되고 있으며, 다른 객체에 잘못 연결될 수도 있습니다.그러니까
rx.observe와rx.observeWeakly를 사용합시다. 이렇게요:view.rx.observe(CGRect.self, "frame") // view의 키가 "frame"이고 CGRect 타입인 객체에 대해 관찰시작 > Observable을 넘겨주는 stream이 생성됩니다. .subscribe(onNext: { frame in // 다음 항목에 대한 구독을 시작합니다 > frame이 변경될 때마다 발생되는 Observable을 구독합니다. print("Got new frame \(frame)") }) .disposed(by: disposeBag) // 처리된 Observable을 DisposeBag에 넣읍시다!혹은
someSuspiciousViewController .rx.observeWeakly(Bool.self, "behavingOk") .subscribe(onNext: { behavingOk in print("Cats can purr? \(behavingOk)") }) .disposed(by: disposeBag)Notifications
Notification을 등록하는 방식도 다음과 같이 대체됩니다.
기존
@available(iOS 4.0, *) public func addObserverForName(name: String?, object obj: AnyObject?, queue: NSOperationQueue?, usingBlock block: (NSNotification) -> Void) -> NSObjectProtocolRx
NotificationCenter.default .rx.notification(NSNotification.Name.UITextViewTextDidBeginEditing, object: myTextView) .map { /*do something with data*/ } ....일시적인 상태
비동기 프로그램을 작성할 때 일시적인 상태와 관련된 많은 문제들이 있습니다. 통상적인 예로는 자동완성박스가 있겠네요.
만약 자동완성 코드를 Rx없이 작성하려면,
abc의c가 입력되었을 때 첫 번째 문제를 만날 수 있습니다 XD.ab에 대한 보류 중인 요청이 있을 때, 보류중인 요청이 취소된다는 것입니다. 좋아요. 이는 풀어내기 크게 어렵지 않습니다. 보류된 요청을 참조하는 변수를 추가로 만들면 되니까요.다음 문제는 만약 요청이 실패했을 때, 엄청난 양의 재시도 로직을 짜야할겁니다. 뭐, 이것도 정리해야하는 재시도 횟수를 파악할 수 있는 몇 가지 변수로 해결할 수 있겠죠.
만약 프로그램이 서버로의 요청하기 전에 몇 초 정도 기다려주면 좋겠네요. 누군가가 뭔갈 계속 입력중이라면 우리 서버에 스팸처럼 계속 요청을 보내고 싶지 않으니까요. 뭐 아마 다른 타이버가 필요하지 않을까요?
검색이 수행중일 동안 어떤걸 보여줘야하는지, 또 요청이 실패해서 재시도 중일 땐 어떤 화면을 보여줘야 할지에 대한 질문도 있을겁니다.
이 모든 것을 작성하고 올바르게 테스트하려면 지루할 것입니다. 이것은 Rx로 쓰여진 동일한 로직입니다.
searchTextField.rx.text .throttle(.milliseconds(300), scheduler: MainScheduler.instance) .distinctUntilChanged() .flatMapLatest { query in API.getSearchResults(query) .retry(3) .startWith([]) // clears results on new search term .catchErrorJustReturn([]) } .subscribe(onNext: { results in // bind to ui }) .disposed(by: disposeBag)추가적인 플래그와 필드가 필요하지 않습니다. Rx는 모든 일시적인 mess를 처리합니다.
Compositional disposal
테이블 뷰에 블러처리된 이미지를 보여주고 싶다고 가정해봅시다. 첫번째로 이미지는 URL로부터 패치되어야 하며, 디코딩 된 다음 블러처리를 해야합니다.
블러처리를 위한 대역폭과 프로세서 시간이 비싸기 때문에 셀이 테이블 뷰 영역에서 보여지지 않으면 전체 프로세스가 취소 될 수 있다면 좋을 것입니다.
사용자가 정말로 빠르게 스와이프하면 많은 요청이 시작되고 취소 될 수 있기 때문에 셀이 가시 영역에 들어가면 즉시 이미지를 가져오기 시작하지 않는다면 좋을 것입니다.
이미지를 흐리게하는 것이 값비싼 작업이기 때문에 동시 이미지 작업의 수를 제한할 수 있다면 좋을 것입니다.
Rx를 사용하면 다음과 같이 처리할 수 있습니다.
// this is a conceptual solution let imageSubscription = imageURLs .throttle(.milliseconds(200), scheduler: MainScheduler.instance) .flatMapLatest { imageURL in API.fetchImage(imageURL) } .observeOn(operationScheduler) .map { imageData in return decodeAndBlurImage(imageData) } .observeOn(MainScheduler.instance) .subscribe(onNext: { blurredImage in imageView.image = blurredImage }) .disposed(by: reuseDisposeBag)이 코드는 모든 작업을 하고 있으며,
imageSubscription이 dispose될 때, 모든 독립적인 비동기 작업을 취소하고 불량 이미지가 UI에 바인딩되지 않도록 합니다.Aggregating network request
만약 두 개의 요청이 발생했고 두 요청이 모두 완료되었을 때 결과를 통합해야 한다면 어떨까요?
zip연산이 있습니다!let userRequest: Observable<User> = API.getUser("me") let friendsRequest: Observable<[Friend]> = API.getFriends("me") Observable.zip(userRequest, friendsRequest) { user, friends in return (user, friends) } .subscribe(onNext: { user, friends in // bind them to the user interface }) .disposed(by: disposeBag)만약 API가 결과를 background 쓰레드에서 넘겨주더라도 바인딩이 main UI 쓰레드를 통해서 해야한다면 어떨까요?
observeOn을 사용할 수 있습니다.let userRequest: Observable<User> = API.getUser("me") let friendsRequest: Observable<[Friend]> = API.getFriends("me") Observable.zip(userRequest, friendsRequest) { user, friends in return (user, friends) } .observeOn(MainScheduler.instance) .subscribe(onNext: { user, friends in // bind them to the user interface }) .disposed(by: disposeBag)Rx는 실제로 더 많은 사례에 적용할 수 있습니다 XD
State
mutation을 허용하는 언어를 사용하면 전역 상태에 쉽게 엑세스하여 변형시킬수 있습니다. 제어되지 않는 공유된 전역 mutation 상태값은 손쉽게 문제가 될 수 있습니다.
하지만 스마트하게 사용되는 명령형 언어는 하드웨어에 더 효율적으로 코드를 작성할 수 있게 해줍니다.
그래서 Rx가 빛나는 거죠(응?)
Rx는 함수형, 명령형 세상 사이에 존재합니다. 불변의 정의와 순수한 함수를 사용하여 변경 가능한 상태의 스냅 샷을 안정적이고 구성 가능한 방식으로 처리 할 수 있습니다.
예를 볼까용?
Easy integration
만약 고유한 observable을 생성해야한다면 어떻게 하나요? 매우 쉽습니다 히힛. 이 코드는 RxCocoa에서 가져왔고
URLSession을 통해 HTTP 요청을 사용하는데 필요한 모든 것입니다.extension Reactive where Base: URLSession { public func response(request: URLRequest) -> Observable<(Data, HTTPURLResponse)> { return Observable.create { observer in let task = self.base.dataTask(with: request) { (data, response, error) in guard let response = response, let data = data else { observer.on(.error(error ?? RxCocoaURLError.unknown)) return } guard let httpResponse = response as? HTTPURLResponse else { observer.on(.error(RxCocoaURLError.nonHTTPResponse(response: response))) return } observer.on(.next(data, httpResponse)) observer.on(.completed) } task.resume() return Disposables.create(with: task.cancel) } } }Benefits
짧게, Rx를 사용하면 당신의 코드를 다음처럼 만들어줍니다:
- Composable(합성가능) : Rx는 Composition의 애칭이래요.
- Reusable(재사용 가능) : 왜냐면 composable 하니까
- Declarative(정의형?) : 정의는 변경 불가하고 데이터만 변경된다.
- Understandable & concise (이해할 수 있고 간결함) : 추상화 수준을 높이고 임시적인 상태값을 제거하니까
- Stable(안정적임) : Rx 코드가 철저한 Unit test를 거쳤습니다.
- Less stateful(상태적이지 않음? 상태에 의존적이지 않음????) : 단방향 데이터 흐름으로 앱을 모델링하기 때문에
- Without leaks(누출없이) : 자원 관리가 쉽다!
이건 아무것도 아냐 ㅎ
앱에 가능한 많은 Rx를 사용하는 게 좋아요. 하지만 특정 케이스에 대한 작업이 존재하는지 다 알 수는 없잖아요.. ㅜ Rx 연산자는 수학에 기반하며, 매우 직관적입니다!
우리에게 이미 익숙한
map,filter,zip,observeOn과 같은 익숙한 것들을 포함하고 있어요.이 연산자들에 대해서는 목록으로 제공되고 있으며, 이해하기 쉽도록 marble diagram을 제공합니다.
만약 추가적으로 연산자가 필요하다면, 당신이 직접 만들 수도 있어요!
찾아보기
- observe vs observeWeakly : 알듯말듯~
- throttle : 이벤트를 일정 주기마다 발생하도록 하는 것. 주어진 시간에 한번만 이벤트가 발생한다. 시간 주기 사이에 들어온 이벤트는 무시되며, 주기가 끝나면 마지막 이벤트만 발생시킨다. vs : Debounce : 이벤트를 그룹화해서 특정시간이 지난 후 하나의 이벤트만 발생하도록 하기. 위와 다른 점은, 이벤트가 발생되면 타이머가 reset된다. throttle는 3초의 주기를 설정하고 매 초마다 이벤트(0,1,2,3,4,5, …)를 발생시킨다면, 이벤트가 처음 시작했을때 0, 3초 뒤에 마지막으로 발생했던 3, 이후 3초 뒤에 6 이런식으로 주기적으로 이벤트가 나온다. 하지만 Debounce의 주기를 3초로 설정하면 (0,1,2,3)의 이벤트가 발생했을 때 마지막 이벤트가 발생된 다음 3초를 기다려서 이벤트가 발생된다. (이전 이벤트는 모두 무시된다.)
observeOn: 가능한 thread 알아두기
원본