Welcome to caution's Blog!
안녕하세요, iOS 개발자 김주희입니다.-
Hash Table
안녕하세요! caution입니다. 오늘은 해시함수에 대해서 배워봅시당.
가격표에 물건의 가격이 적혀져 있는데, 물건의 가격을 찾기 위해서 얼마만큼의 시간이 소요될까요? 가격표가 이름 순으로 정렬되어 있지 않아 단순 탐색으로 진행한다면 O(n) 시간이, 정렬되어 있어 이진 탐색으로 찾아본다면 O(log n) 시간이 걸릴겁니다. 만약 가격표를 다른 직원이 모두 외우고 있다면 어떨까요? 그 직원에게 물어본다면 O(1) 시간 만에 가격을 알려줄 수 있을 겁니다. 이름으로 가격을 바로 검색할 수 있는 자료구조를 만들어봅시다.
Hash 함수
해시 함수는 문자열을 받아서 이 문자열에 대한 숫자를 할당해주는 함수입니다. 해시 함수는 다음과 같은 요건을 갖추어야 합니다.
해시함수에는 일관성이 있어야 합니다. 같은 문자열을 넣으면 항상 같은 수가 나와야 합니다. 다른 문자열을 넣으면 다른 숫자가 나와야 합니다. 예를 들어 어떤 단어를 넣어도 1만 나온다면 좋은 해시 함수가 아닙니다. 가장 좋은 경우는 서로 다른 단어에 대해 모두 서로 다른 숫자가 나와야 합니다.
가격표로 크기가 5인 배열이 있다고 생각해봅시다. 우리는 모든 물건의 가격을 이 배열에 넣을 겁니다.
index 0 1 2 3 4 가격 먼저 사과의 가격을 추가합니다. 해시함수에 apple를 넣으면 3이 나옵니다. 그럼 apple의 가격은 3번 index에 넣을 겁니다.
index 0 1 2 3 4 가격 1 물건 apple 다음으로 우유를 추가합니다. 해시함수에 milk를 넣으면 0이 나옵니다. 그럼 milk의 가격은 0번 index에 넣을 겁니다.
index 0 1 2 3 4 가격 1.5 1 물건 milk apple 이런 방식을 반복하면 가격표를 모두 채울 수 있습니다.
index 0 1 2 3 4 가격 1.5 0.8 2.5 1 0.6 물건 milk banana beer apple coke 아이스크림의 가격을 알아보려면 어떻게 해야할까요? 해시함수에 coke를 넣으면 4가 나오겠죠? 그렇기 때문에 전체 가격표를 훑어볼 필요 없이 바로 4번째 배열의 값을 가져오면 됩니다. 바로 탐색 없이 가격을 가져오기 때문에 O(1)의 매우 빠른 시간으로 데이터를 가져올 수 있습니다.
해시 함수는 배열이 얼마나 큰지 알고 있어야 하며, 유효한 인덱스만 반환해야 합니다. 배열이 5개의 원소만 가질 수 있다면 10을 반환해서는 안됩니다.
이때 해시 테이블의 상품 이름은 키(Key)가 되고, 가격은 값(Value)이 됩니다. 해시 테이블은 키에 대한 값을 할당하는 자료구조입니다.
swift에도 해시함수가 있을까요? swift에서는 Dictionary의 이름을 가진 해시 테이블이 존재합니다. 다음과 같이 사용해볼 수 있죠.
var dictonary: [String:Int] = [:] dictonary["milk"] = 1500 dictonary["banana"] = 800 print(dictonary["milk"]) //1500해시테이블을 사용하는 예
해시 테이블을 사용하면 키 값을 알고 있을 때 매우 빠르게 데이터에 접근할 수 있습니다. 예를 들어 DNS를 해시 테이블로 사용할 수도 있겠죠.
var dns: [String:String] = [:] dns["google.com"] = "74.125.239.133" dns["naver.com"] = "173.252.120.6"또한 해시 테이블에서는 키-값이 1:1 매칭이기 때문에 중복 항목을 방지할 수 있습니다. 유권자의 투표 여부를 확인하려면 어떻게 해야할까요?
var voted: [String:Bool] = [:] func checkVotable(identifier: String) -> Bool { return voted[identifier] == nil } func vote(identifier: String) { guard checkVotable(identifier: identifier) else { print("이미 투표했습니다.") return } // 투표를 한다. voted[identifier] = true }해시 테이블에 이미 유권자에 대한 값이 존재한다면 이 사람은 이미 투표를 했다는 걸 알 수 있습니다.
해시 테이블은 캐싱에도 사용할 수 있습니다. 키를 URL로 하고 그에 대응하는 자료를 할당하여 사용할 수 있습니다.
var cache: [URL:Any] = [:] func load(url: URL) -> Any { if let cacheData = cache[url] { return cacheData } else { let data = requestData() cache[identifier] = data return data } }그럼 캐싱된 데이터가 있다면 그 데이터를 넘겨주고, 캐싱된 데이터가 없을 때에만 데이터를 요청할 수 있습니다.
충돌
아까 우리는 5개의 물건의 가격을 담을 수 있는 가격표를 해시 테이블로 만들었습니다.
index 0 1 2 3 4 가격 1500 800 2500 1000 600 물건 milk banana beer apple coke 이번엔 다른 방식으로 가격표를 만들어보죠. 26개의 공간이 있는 배열을 가격표로 지정합니다.
index 0 1 2 3 4 5 … 23 24 25 가격 물건 이번에는 물건의 첫 글자에 따라 공간을 할당하는 방식의 해시 함수를 사용하겠습니다. 먼저 apple은 가장 첫 번째 공간에 들어갈겁니다.
index 0 1 2 3 4 5 … 23 24 25 가격 1 물건 apple 다음으로 banana를 index 1에 넣겠습니다.
index 0 1 2 3 4 5 … 23 24 25 가격 1 0.8 물건 apple banana 자 이제 beer를 넣어보죠. 이때 문제가 발생합니다. beer의 첫 글자는 b 니까 index 1에 넣어야 하는데 이미 banana가 들어가 있습니다. 그럼 beer를 넣기 위해 banana를 덮어쓰게 됩니다. banana의 가격을 요청했지만 beer의 가격을 넘겨주게되죠. 이러한 현상을 충돌 이라고 합니다.
이 충돌을 해결하기 위해선 어떻게 해야할까요? 여러 가지 방법이 있지만, 간단한 방법 중 하나는 같은 공간( index 1 )에서 여러 개의 키를 연결 리스트로 만들어 넣는 겁니다.
그럼 b로 시작하는 어떤 물건을 찾기 위해서는 이 연결 리스트를 탐색해야합니다. 연결 리스트가 커질 수록 물건을 찾는 시간이 O(n)이므로 길어지겠죠.
- 해시 함수가 매우 중요합니다. 방금 전의 해시 함수는 여러 키를 하나의 공간에 할당하는 문제가 발생합니다. 이상적으로는 해시 함수는 키를 해시 테이블 전체에 고르게 할당해야 합니다.
- 만약 연결 리스트가 길어지면 해시 테이블의 속도도 느려집니다. 좋은 해시 함수가 있다면 이런 일이 발생하지 않겠죠!
해시 테이블의 성능
해시 테이블의 성능은 어떻게 될까요? 앞서 말한 것과 같이 연결 리스트가 길어진다면 해시 테이블의 속도가 매우 떨어지게 됩니다. 그래서 평균적인 성능과 최악의 성능을 비교해볼 수 있겠죠.
Hash Table 평균 Hash Table 최악 Array Linked List 탐색 O(1) O(n) O(1) O(n) 삽입 O(1) O(n) O(n) O(1) 삭제 O(1) O(n) O(n) O(1) 평균적인 경우 해시 테이블의 성능을 살펴보면 탐색을 할 때 배열만큼 빠릅니다. 그리고 삽입이나 삭제에서는 연결 리스트만큼 빠릅니다. 평균적인 상황에서는 매우 빠른 자료구조입니다. 하지만 최악의 경우에는 해시 테이블이 가장 느리기도 합니다. 따라서 최악의 상황이 발생하지 않도록 하는 것이 좋습니다. 이를 위해서는 충돌을 피해야 하고, 충돌을 피하려면 다음과 같은 것이 필요합니다.
- 낮은 사용률
- 좋은 해시함수
사용률
해시 테이블의 사용률을 계산하는 방법은 다음과 같습니다.
해시 테이블에 있는 항목 수 / 해시 테이블 공간 크기
해시 테이블의 모든 공간에 항목이 들어가 있다면, 해시 테이블의 사용량은 1이 될 겁니다. 사용량이 1보다 크다는 것은 공간보다 항목의 수가 많다는 뜻이므로, 해시 테이블의 공간을 추가해야 합니다. 이를 리사이징 이라고 합니다.
index 0 1 2 3 4 가격 1.5 0.8 2.5 1 0.6 물건 milk banana beer apple coke 앞 서 만들었던 가격표를 다시 봅시다. 이때 신제품인 coffee를 추가해야한다면 이 테이블을 리사이징 해야 합니다. 보통은 두 배 정도 큰 배열을 만드는 것이 보통입니다.
index 0 1 2 3 4 5 6 7 8 9 가격 1.5 0.8 2.5 1 0.6 물건 milk banana beer apple coke 이제 coffee를 넣을 수 있겠네요.
index 0 1 2 3 4 5 6 7 8 9 가격 1.5 0.8 2.5 1 0.6 2 물건 milk banana beer apple coke coffee 새로 만들어진 해시 테이블의 사용률은 6/10 입니다. 사용률이 낮을 수록 충돌이 적게 일어나고, 해시 테이블의 성능 또한 좋아집니다. 이 리사이징은 엄청 비싼 작업이기 때문에 자주 일어나는 것은 좋지 않습니다. 보통은 사용률이 0.7보다 커지면 리사이징 하며, 해시 테이블은 리사이징을 해도 O(1)의 시간이 걸립니다.
정리하기
- 해시 테이블은 해시 함수와 배열을 결합해서 만듭니다.
- 충돌은 해시 테이블의 성능을 떨어뜨리기 때문에 충돌을 줄이는 해시 함수가 있어야 합니다.
- 해시테이블은 탐색, 삽입, 삭제 속도가 매우 빠른 상수시간을 가집니다.
- 해시 테이블은 어떤 항목과 다른 항목의 관계를 모형화 하는 데 좋습니다.
- 보통 사용율이 0.7보다 커지면 해시 테이블을 리사이징합니다.
- 해시 테이블은 데이터를 캐싱하는 데도 사용되고, 중복을 잡아내는 데에도 뛰어납니다.
참조
-
HTTP
안녕하세요! caution입니다.
암호화 방식
대칭 키 암호화
동일하게 암호화를 풀어내는 방식(키)를 가지고 있어서 암호화된 파일을 해독할 수 있다. 둘 다 모두 동일한 키를 가지고 있어야 한다. 맨 초기에 키를 함께 전송한다면 중간에 가로채서(Man in the Middle Attack) 문제가 발생할 수 있다.
비대칭 키 암호 (공개키 방식)
공개키와 개인키 두 개의 키로 서로 암호화와 복호화를 한다. 공개키로 암호화하면 개인키로 복호화 할 수 있으며 개인키로 암호화하면 공개키로 복호화할 수 있다. B가 A에게 메세지를 보내려고 한다.
- B->A 연결한다.
- A->B에게 공개 키(public key)를 보내고 개인 키(private key)는 보내지 않는다.
- B->A 이 공개키로 메시지를 암호화하여 전송한다.
- A가 개인키로 복호화한다.
대칭 암호화는 빠르고 비대칭 암호화는 신뢰성이 높지만 메세지만 전달하는 것보다 느리다.
그래서 대칭키를 교환할 때에만 비대칭 암호화(공개키방식)를 사용한다. 실제 데이터는 대칭키 방식으로 암호화를 한다.
SSL
신뢰할 만한 인증 기관(CA)이 발행한 인증서를 2단계에서 public key 와 함께 보낸다.
SSL 인증서의 내용
- 서비스의 정보 : 인증서를 발급한 CA, 서비스 도메인
- 서버 측 공개키 : 공개키의 내용, 공개키의 암호화 방법 위 내용은 CA에 의해서 공개키 방식으로 암호화된다.
SSL 통신 단계
STEP 1. 악수(Handshake)
상대가 존재하는지, 데이터를 주고 받기 위해 어떤 방법을 사용해야 하는지를 파악합니다. 브라우저와 서버가 핸드쉐이크를 하면서 SSL 인증서를 주고 받습니다.
- Client Hello : 클라이언트가 서버에 접속합니다.
- 클라이언트 측에서 생성한 랜덤 데이터를 전송합니다.
- 클라이언트가 지원하는 암호화 방식들을 전송합니다.
- 이미 SSL Handshaking을 했다면 기존 세션을 재활용하기 위해서 세션 아이디를 전송합니다.
- Server Hello : 서버가 클라이언트에게 데이터를 전송합니다.
- 서버가 생성한 랜덤 데이터를 전송합니다.
- 서버가 선택한 클라이언트 암호화 방식을 전달합니다.
- SSL 인증서를 전송합니다.
- 서버의 인증서가 CA에 의해서 발급된 건지 확인합니다.
- 브라우저는 CA 리스트와 함께 각 기관별 공개키를 가지고 있습니다. 이를 이용해서 인증서를 복호화에 성공하면 이 인증서를 전송한 서버를 믿을 수 있게 됩니다.
- pre master secret = 서버의 랜덤 데이터 + 클라이언트의 랜덤 데이터
- pre master secret 키를 SSL 인증서 안에 있던 서버의 공개키로 암호화를 하여 서버에 전송합니다.
- 서버가 클라이언트가 전송한 pre master secret 키를 개인키로 복호화 합니다.
- 이를 기반으로 master secret > session key를 생성합니다.
- 이 session key를 대칭키로 사용하여 데이터를 암호화 하여 주고 받습니다.
- 클라이언트와 서버는 Handshake 단계가 종료되었음을 알려줍니다.
STEP 2. 세션
실제로 서버와 클라이언트가 데이터를 주고 받는 단계입니다. session key를 이용해서 대칭키 방식으로 암호화하여 전송합니다. 클라이언트와 서버가 모두 session key를 가지고 있기 때문에 서로 암호화 복호화가 가능합니다.
STEP 3. 세션 종료
데이터의 전송이 끝나면 SSL 통신이 끝났음을 알려준다. 세션키를 폐기한다.
HTTP Method

POST는 새로운 곳에 리소스가 계속 추가되는 것 (insert)PUT은 지정된 위치에 생성 또는 업데이트 하는 것 (update) : 몇 번이고 반복해도 같은 값이 나온다.OPTIONS: 웹서버에서 지원되는 메소드의 종류를 확인할 경우 사용.CONNECT: 동적으로 터널 모드를 교환, 프락시 기능을 요청시 사용.TRACE: 원격지 서버에 루프백 메시지 호출하기 위해 테스트용으로 사용.Response Code
100 : 정보 전송, 임시응답
응답코드 오류 설명 100 Continue 클라이언트로 부터 일부 요청을 받았으며 나머지 정보를 계속 요청함 101 Switching protocols 200 : 성공
응답코드 오류 설명 200 OK 201 Created 202 Accepted 203 Non-authoritative information 서버가 클라이언트 요구 중 일부만 전송 204 No content PUT,POST,DELETE Request가 성공했지만 전송할 데이터가 없음 300 : 리다이렉션
응답코드 오류 설명 301 Moved permanently 요구된 데이터를 변경된 타 URL에 요청함 302 Not temporarily 304 Not modified 로컬 캐시 정보 사용 400 : 클라이언트 요청에러
응답코드 오류 설명 400 Bad Request 사용자의 잘못된 요청을 처리할 수 없음 401 Unauthorized 인증이 필요한 페이지를 요청한 경우 402 Payment required 예약됨 403 Forbidden 접근 금지 404 Not found 요청 페이지 없음 405 Method not allowed 허가되지 않은 http method 사용 407 Proxy authentication required 프락시 인증 요구됨 408 Request timeout 요청 시간 초과 410 Gone 영구 사용 금지 412 Precondition failed 전제조건 실패 414 Request-URI too long 500 : 서버 오류
응답코드 오류 설명 500 Internal server error 내부 서버 오류 501 Not implemented 웹 서버가 처리할 수 없음 503 Service unnailable 서비스 제공 불가 504 Gateway timeout 게이트웨이 시간 초과 505 HTTP version not supported 해당 HTTP 버전 지원되지 않음 Timeout
- Connection time : 클라이언트가 서버와 연결할 때까지 걸리는 시간
- Read time : 클라이언트가 서버에 연결한 뒤 응답을 받을 때까지 걸리는 시간
참조
-
컴퓨터 시스템으로의 여행
- 1.1 정보는 비트와 컨텍스트로 이루어진다.
- 1.2 프로그램은 다른 프로그램에 의해 다른 형태로 번역된다.
- 1.3 컴파일 시스템이 어떻게 동작하는지 이해하는 것은 중요하다.
- 1.4 프로세서는 메모리에 저장된 인스트럭션을 읽고 해석한다.
- 1.4.1 시스템의 하드웨어 조직
- 1.4.2 hello 프로그램의 실행
- 1.5 캐시가 중요하다.
- 1.6 저장장치들은 계층구조를 이룬다.
- 1.7 운영체제는 하드웨어를 관리한다.
- 1.8 시스템은 네트워크를 이용하여 다른 시스템과 통신한다.
- 1.9 중요한 주제들
- 1.10 요약
안녕하세요! caution입니다. 오늘의 컨텐츠는 컴퓨터 시스템 제 3판의 1장 내용입니다.
1.1 정보는 비트와 컨텍스트로 이루어진다.
#include <studio.h> int main() { printf("hello, world\n"); return 0; }위의 hello 프로그램은 프로그래머가 에디터로 작성한 소스프로그램이며,
hello.c라는 텍스트 파일로 저장됩니다. 소스 프로그램은 0 또는 1로 표시되는 비트들의 연속이며, 바이트라는 8비트 단위로 구성됩니다. 대부분의 컴퓨터 시스템은 텍스트 문자를 ASCII 표준을 사용하여 표시합니다.hello.c프로그램은 연속된 바이트들로 파일에 저장되며, 각 바이트는 특정 문자에 대응되는 정수값이 존재합니다. 예를 들어 첫 번째 바이트는 35인데, 이는 문자 ‘#’에 대응됩니다. 이처럼 오로지 아스키 문자들로만 이루어진 파일들을 텍스트 파일이라고 부르며, 다른 모든 파일들은 바이너리 파일이라고 합니다. 모든 시스템 내부의 정보는 비트들로 표시됩니다.1.2 프로그램은 다른 프로그램에 의해 다른 형태로 번역된다.
hello 프로그램은 인간이 읽을 수 있는 언어로 작성되어있습니다. 하지만 시스템에서 이 프로그램을 실행시키려면 각 문장을 저급 기계어 인스트럭션들로 번역되어야 합니다. 이 인스트럭션들은 “실행가능 목적 프로그램(Executable object Program)”이라고 하는 바이너리 디스크 파일로 저장됩니다. 유닉스 시스템에서 소스파일을 오브젝트 파일로 번역하는 방법은 다음과 같습니다.
linux> gcc -o hello hello.cGCC 컴파일러 드라이버는 소스파일
hello.c를 읽어서 실행파일인 hello 로 번역합니다. 번역은 다음 4개의 단계를 거쳐서 실행됩니다.각각의 단계를 수행하는 프로그램들 - 전처리기, 컴파일러, 어셈블러, 링커 - 을 합쳐서 컴파일 시스템이라고 합니다.
- 전처리 단계 : 전처리기는 본래의 C 프로그램을 # 문자로 시작하는 디렉티브에 따라 수정합니다. 우리의
hello.c파일 첫 줄의#include<studio.h>는 전처리기에게 시스템 헤더파일인studio.h를 프로그램 문장에 직접 삽입하라고 지시합니다. 이 결과는.i로 끝나는 프로그램이 생성됩니다. - 컴파일 단계 : 컴파일러는
hello.i를hello.s로 번역하며, 이 파일에는 어셈블리어 프로그램이 저장됩니다. 어셈블리어는 상위수준 컴파일러를 위한 공통의 출력언어를 제공함으로 유용합니다.main: subq $8, %resp movl $.LCO, %edi call puts movl $0, %eax addq #8, %rsp ret - 어셈블리 단계 : 어셈블러가
hello.s를 기계어 인스트럭션으로 번역하고, 재배치가능 목적프로그램의 형태로 묶어서hello.o라는 목적 파일에 저장합니다. 이 파일은 main 함수의 인스트럭셔들을 인코딩하기 위한 17바이트를 포함하는 바이너리 파일입니다. - 링크 단계 : hello 프로그램에서 호출하는 printf 함수는 표준 C 라이브러리에 포함되어 있으며, 이미 컴파일된 별도의 목적파일인
printf.o에 들어있습니다. 링커는print.o파일과hello.o파일을 연결해줍니다. 이 결과 실행가능 목적파ㅇㅣㄹㄹㅗ 메모리에 적재되어 시스템에 의해 실행됩니다.
1.3 컴파일 시스템이 어떻게 동작하는지 이해하는 것은 중요하다.
프로그램 성능 최적화하기
최신 컴파일러들은 복잡한 도구로 대개 우수한 코드를 생성하고 최적화를 지원합니다. 하지만 프로그래머로서 효율적인 코드를 작성하기 위해서는 기계어 수준 코드에 대한 기본적인 이해를 할 필요가 있으며 컴파일러가 어떻게 C 문장들을 기계어 코드로 번역하는지 알 필요가 있습니다. 예를 들어 switch문은 if-else 문을 연속해서 사용하는 것보다 언제나 더 효율적일까? 함수 호출 시 발생하는 오버헤드는 얼마나 되는가? while 루프는 for 루프보다 효율적일까? 포인터 참조가 배열 인덱스보다 더 효율적인가? 합계를 지역변수에 저장하면 참조형태로 넘겨받은 인자를 사용하는 것보다 왜 루프가 더 빨리 실행되는가? 수식 연산시 괄호를 단순히 재배치 하기만 해도 함수가 더 빨리 실행되는 이유는 무엇인가?
링크 에러 이해하기
링커가 어떤 참조를 풀어낼 수 없다고 할 때는 무엇을 의미하는가? 정적변수와 전역변수의 차이는 무엇인가? 만일 각기 다른 파일에 동일한 이름의 두 개의 전역변수를 정의한다면 무슨 일이 일어나는가? 정적 라이브러리와 동적 라이브러리의 차이는 무엇인가? 컴파일 명령을 쉘에서 입력할 때 명령어 라인의 라이브러리들의 순서는 무슨 의미가 있는가? 가장 겁나는 질문인, 왜 링커와 관련된 에러들은 실행하기 전까지는 나타나지 않는 걸까?
보안 약점 피하기
오랫동안 버퍼 오버플로우 취약성이 인터넷과 네트워크상의 보안 약점의 주요 원인으로 설명되었다. 이 취약성은 프로그래머들이 신뢰할 수 없는 곳에서 획득한 데이터의 양과 형태를 주의 깊게 제한해야 할 필요를 거의 인식하지 못하기 때문에 생겨난다. 안전한 프로그래밍을 배우는 첫 단계는 프로그램 스택에 데이터와 제어 정보가 저장되는 방식 때문에 생겨나는 영향을 이해아흔 ㄴ것입니다.
1.4 프로세서는 메모리에 저장된 인스트럭션을 읽고 해석한다.
hello.c소스 프로그램은 컴파일 시스템에 의해 hello라는 실행 가능한 목적파일로 번역되어 디스크에 저장되었습니다. 이 실행파일을 유닉스 시스템에서 실행하기 위해서는 쉘에서 그 이름을 입력하면 됩니다.linux> ./hello hello, world linex>입력된 명령어
./hello는 내장 쉘 명령어가 아니기 때문에 실행파일의 이름으로 판단하고 파일을 로딩하고 실행해 주고, 이 프로그램이 종료되기를 기다립니다. hello 프로그램은 메세지를 화면이 출력하고 종료됩니다. 쉘은 프롬프트를 출력해주고 다음 입력 명령어 라인을 기다립니다.1.4.1 시스템의 하드웨어 조직
hello 프로그램을 실행할 때 무슨 일이 일어나는지 설명하기 위해서는 전형적인 시스템에서의 하드웨어 조직을 이해할 필요가 있습니다.

버스
시스템 내를 관통하는 전기적 배선군을 버스라고 하며, 컴포넌트들 간에 바이트 정보들을 전송한다. 버스는 일반적으로 word(32비트 : 4바이트 /64비트 : 8바이트)단위로 데이터를 전송하도록 설계된다.
입출력 장치
입출력 장치는 시스템과 외부세계와의 연결을 담당한다. 예제 시스템은 네 개의 입출력 장치를 가지고 있다. 마우스, 키보드, 디스플레이, 디스크 드라이브. hello 실행파일은 디스크에 저장되어 있다. 각 입출력 장치는 입출력 버스와 컨트롤러나 어댑터를 통해 연결된다. 이 두 장치의 차이는 패키징에 있다. 컨트롤러는 디바이스 자체가 칩셋이거나 메인보드에 장착된다. 어댑터는 메인보드의 슬롯에 장착되는 카드이다.
메인 메모리
메인 메모리는 프로세서가 프로그램을 실행하는 동안 데이터와 프로그램을 모두 저장하는 임시 저장장치다. 물리적으로 메인 메모리는 DRAM 칩들로 구성되어 있다. 논리적으로 메모리는 연속적인 바이트들의 배열로 0부터 시작해서 각 고유의 주소를 가진다.
프로세서
주처리장치(CPU) or 프로세서는 메인 메모리에 저장된 인스트럭션들을 해독하는 엔진이다. 프로세서의 중심에는 word 크기의 저장장치(Register)인 프로그램 카운터(PC)가 있다. 프로세서는 PC가 가리키는 곳의 메모리로부터 인스트럭션을 읽어오고, 비트들을 해석하여 지정된 동작을 실행한다. 그리고 PC를 다음 인스트럭션 위치로 업데이트 한다.(이 새로운 위치는 이전의 인스트럭션과 메모리 상에서 연속적일 수도 있고, 그렇지 않을 수도 있다.) 프로세서는 메인 메모리, 레지스터 파일, ALU(수식/논리 처리기) 주위를 순환한다. 레지스터 파일은 각각 고유의 이름을 갖는 word 크기의 레지스터 집합으로 구성되어 있다. ALU는 새 데이터와 주소 값을 계산한다.
- 적재(Load) : 메인 메모리에서 레지스터에 1 byte or 1 word를 이전 값에 덮어쓰는 방식으로 복사한다.
- 저장(Store) : 레지스터에서 메인 메모리로 1 byte or 1 word를 이전 값을 덮어쓰는 방식으로 복사한다.
- 작업(Operate) : 두 레지스터의 값을 ALU로 복사하고 두 개의 워드로 수식연산을 수행한 뒤, 결과를 덮어쓰기 방식으로 레지스터에 저장한다.
- 점프(Jump) : 인스트럭션 자신으로부터 1 word를 추출하고 이를 PC에 덮어쓰기 방식으로 복사한다.
1.4.2 hello 프로그램의 실행
앞 서 작성했던 hello 프로그램을 실행시켰을 때 무슨 일이 일어나는지 자세히 살펴보자.
Step 1
- 쉘 프로그램을 실행시키고 “./hello”를 입력한다.
- 메인 메모리에 “./hello”가 저장된다. USB Controller - Keyboard » I/O bridge » Bus Interface » Register file » Bus Interface » I/O bridge » Main Memory
Step 2
- 엔터를 누른다. 파일의 코드와 데이터를 복사하는 인스트럭션을 실행한다.
- hello를 디스크에서 메인 메모리로 로딩한다.
- 출력 문자열인 “hello, world\n”이 메인 메모리에 포함된다. Disk » Disk Controller » I/O bridge » Main Memory
Step 3
- hello 프로그램의 main 루틴의 인스트럭션을 실행한다.
- “hello, world\n” 문자열을 메인 메모리로부터 레지스터로 복사한다.
- 문쟈열을 디스플레이 장치로 전송하여 화면에 글자들이 표시된다. Main memory » I/O bridge » Bus Interface » Register file » Bus Interface » I/O bridge » Graphics adapter
1.5 캐시가 중요하다.
위의 시나리오를 보면 시스템이 정보를 이동시키는 일에 매우 많은 시간을 보낸다는 것이다. 이러한 복사과정들이 프로그램의 실제 작업을 느리게 하는 오버헤드이다. 그래서 시스템 설계자들은 이러한 복사과정을 가능한 빠르게 동작하도록 설계하려고 한다. 물리학의 법칙 때문에 더 큰 저장장치들은 더 작은 저장장치들보다 느린 속도를 갖는다. 하지만 더 빠른 장치를 만드는 것은 더 많은 비용이 든다.(당연하게도)
시스템 드라이브는 메인 메모리보다 1,000 배 크기가 크지만 프로세서가 디스크에서 1 word의 데이터를 읽어드리는 데는 천만 배 더 오래걸릴 수 있다. 레지스터 파일은 수백 바이트를 저장하지만 메인 메모리는 십억 바이트를 저장한다. 프로세서는 레지스터 파일의 데이터를 읽는데 메모리보다 100배 이상 빨리 읽을 수 있다.
프로세서-메모리 간 속도 격차가 지속적으로 증가함에 대응하기 위해서 작고 빠른 캐시 메모리를 고안하여 프로세서가 단기간에 필요로 할 가능성이 높은 정보를 임시로 저장할 목적으로 사용한다.
1.6 저장장치들은 계층구조를 이룬다.
모든 컴퓨터 시스템의 저장장치들은 다음과 같은 메모리 계층구조로 구성되어 있다. 계층의 곡대기에서부터 맨 밑바닥까지 이동할수록 저장장치들을 더 느리고, 크고, 비용이 싸진다.
 레지스터 파일은 가장 최상위인 레벨 0에 해당하며 L1-L3의 캐시를 가진다. 메인 메모리는 다음 계층에 속한다. 이러한 메모리 계층 구조의 주요 아이디어는 한 레벨의 저장장치가 다음 하위레벨 저장장치의 캐시 역할을 안하는 것이다. L1과 L2의 캐시는 L2와 L3이며, 디스크의 캐시는 메인 메모리다.
레지스터 파일은 가장 최상위인 레벨 0에 해당하며 L1-L3의 캐시를 가진다. 메인 메모리는 다음 계층에 속한다. 이러한 메모리 계층 구조의 주요 아이디어는 한 레벨의 저장장치가 다음 하위레벨 저장장치의 캐시 역할을 안하는 것이다. L1과 L2의 캐시는 L2와 L3이며, 디스크의 캐시는 메인 메모리다.1.7 운영체제는 하드웨어를 관리한다.
셀 프로그램이 hello 프로그램을 로드하고 실행할 때, 또 hello 프로그램이 메시지를 출력할 때, 프로그램이 키보드나 디스플레이, 디스크나 메인 메모리를 직접 엑세스하지 않고 운영체제가 제공하는 서비스를 활용한다. 운영체제는 응용프로그램이 하드웨어를 잘못 사용하는 것을 막고 단순하고 균일한 메커니즘을 사용하여 복잡한 저수준 하드웨어 장치들을 조작할 수 있도록 하기 위해 이를 추상화한다.
1.7.1 프로세스
셀 프로그램이나 hello 같은 프로그램이 실행될 때 운영체제는 시스템에서 이 한 개의 프로그램만 실행되는 것 같은 착각에 빠지도록 해준다. 프로세서가 프로그램 내의 인스트럭션들을 다른 방해 없이 순차적으로 실행하고, 프로세서, 메인 메모리, 입출력장치들을 이 프로그램이 모두 독차지 하는 것처럼 보인다. 이러한 동작이 가능한 것은 프로그램에 대한 운영체제의 추상화인 프로세스라는 개념 때문이다. 다수의 프로세스들은 동일한 시스템에서 동시에 실행될 수 있으며, 하드웨어를 배타적으로 사용하는 것처럼 느껴진다. 대부분의 시스템에서 CPU의 수보다 실행가능한 프로세스 수가 더 많다. 이는 프로세서가 프로세스들을 교차하면서 실행시키는 방식(context switching)으로 CPU가 다수의 프로세스를 동시에 실행하는 것처럼 보이게 해준다. 운영체제는 프로세스가 실행하는 데 필요한 모든 상태정보의 변화를 추적한다. 이러한 상태정보들을 context라고 부르는데, Context에는 PC, register file, main memory의 현재 값을 포함하고 있다. context switching이 발생하면 운영체제는 현재 프로세스의 Context를 저장하고 새 프로세스의 컨텍스트를 복원시키며 제어권을 새 프로세스로 넘겨준다. 이러한 프로세스 전환은 운영체제 커널에 의해 관리된다. 커널은 운영체제 코드의 일부분으로 메모리에 상주하고 있다. 응용프로그램이 운영체제에 어떤 작업을 요청하면, 특정한 시스템 콜을 실행해서 커널에 제어를 넘겨준다. 그러면 커널이 요청된 작업을 수행하고 다시 응용프로그램으로 리턴한다. 커널은 별도 프로세스가 아니라 모든 프로세스를 관리하기 위해 시스템이 이용하는 코드와 자료구조의 집합이다.
1.7.2 스레드
프로세스는 스레드라 불리는 다수의 실행 유닛으로 구성되어 있다. 각각의 스레드는 해당 프로세스의 컨텍스트에서 실행되며 동일한 코드와 전역 데이터를 공유한다. 그렇기 때문에 스레드간 데이터 공유가 쉽다. 스레드는 독립적인 실행 흐름이기 때문에 독립적으로 함수 호출이 가능해야 한다. 그러기 위한 최소 조건으로 독립된 스택을 할당해야한다. 스택에는 함수 호출 시 전달되는 인자, 되돌라갈 주소값, 함수내에서 선언하는 변수 등을 저장하고 있다. 스레드는 CPU를 할당받았다가 스케줄러에 의해 다시 선점당하기 때문에 어디까지 수행되었는지 기억해야 한다. 그렇기 때문에 PC 레지스터를 독립적으로 할당한다.
멀티 스레딩 시 주의해야할 점
멀티 프로세스 기반으로 프로그래밍 할 때는 프로세스 간 공유자원이 없기 때문에 동일한 자원에 동시접근할 일이 없었지만 멀티 스레딩 시에는 데이터와 힙 영역을 공유하기 때문에 어떤 스레드가 다른 스레드에서 사용중인 변수나 자료구조에 접근하여 엉뚱한 값을 읽어오거나 수정할 수도 있다. 이로 인한 동기화작업이 필요하다. 동기화를 통해 작업 처리 순서를 컨트롤하고 공유 자원에 대한 접근을 컨트롤 해야한다. 하지만 이 또한 병목현상이 발생할 수 있기 때문에 과도한 락을 걸지 않도록 주의해야 한다.
멀티 스레드 vs 멀티 프로세스
멀티 스레드는 멀티 프로세스보다 적은 메모리 공간을 차지하고 context switching이 빠르다는 장점이 있지만 오류로 인해 하나의 스레드가 종료되면 다른 스레드에 영향을 줄 수 있다는 점과 동기화 문제를 안고 있다. 반면 멀티 프로세스는 한 프로세스가 죽더라도 다른 프로세스에 영향을 끼치지 않고 정상적으로 수행되지만 멀티 스레드에 비해 많은 메모리 공간과 CPU를 차지한다는 단점이 존재한다.
1.7.3 가상메모리
가상메모리는 각 프로세스들이 메인 메모리 전체를 독점하고 있는 것 같은 환상을 제공하는 추상화이다. 각 프로세스는 가상주소 공간을 가지는데 이는 다음과 같은 메모리 구조를 가진다.
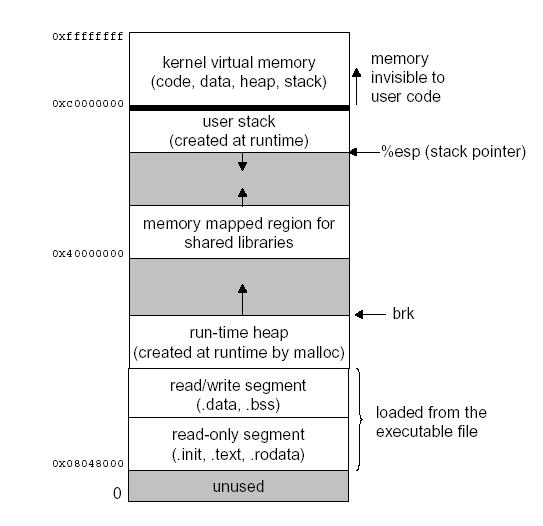 리눅스에서 주소공간의 최상위 영역은 모든 프로세스들이 공통으로 사용하는 운영체제의 코드와 데이터(커널) 을 위한 공간이다. 주소공간의 하위영역은 사용자 프로세스의 코드와 데이터를 저장한다.
리눅스에서 주소공간의 최상위 영역은 모든 프로세스들이 공통으로 사용하는 운영체제의 코드와 데이터(커널) 을 위한 공간이다. 주소공간의 하위영역은 사용자 프로세스의 코드와 데이터를 저장한다.프로그램 코드와 데이터
코드는 모든 ㅡ로세스들이 같은 고정 주소에서 시작하며, 그 다음 C 전역 변수에 대응되는 데이터 위치들이 따라온다.
힙(Heap)
코드와 데이터 영역 다음으로 런타임 힙이 따라온다. 힙은 프로세스가 실행되면서
malloc이나free를 호출하면서 런타임에 동적으로 그 크기가 늘었다 줄었다 한다.공유 라이브러리
주소공간의 중간에 C 표준 라이브러리나 수학 라이브러리와 같은 공유 라이브러리의 코드와 데이터를 저장하는 영역이 있다.
Stack
사용자 가상메모리 공간의 맨 위에 컴파일러가 함수 호출을 구현하기 위해 사용하는 사용자 스택이 위치한다. 힙과 마찬가지로 사용자 스택은 프로그램이 실행되는 동안에 동적으로 늘어났다 줄어들었다 한다. 함수를 호출할 때마다 스택이 커지며, 함수에서 리턴될 때에는 줄어든다.
Kernel Virtual Memory
주소공간의 맨 윗부분은 커널을 위해 예약되어 있다. 응용프로그램들은 이 영역의 내용을 읽거나 쓰는 것이 금지되어 있으며, 커널 코드 내에 정의된 함수를 직접 호출하는 것도 금지되어 있다.
1.7.4 파일
파일은 연속된 바이트들로, 디스크, 키보드, 디스플레이, 네트워크까지 포함하는 모든 입출력장치는 파일로 모델링한다. 시스템의 모든 입출력은 유닉스I/O라는 시스템 콜들을 이용하여 파일을 읽고 쓰는 형태로 이루어진다. 이를 통해 프로그래머는 디스크 기술에 대해서는 몰라도 된다.
1.8 시스템은 네트워크를 이용하여 다른 시스템과 통신한다.
네트워크는 또 하나의 입출력 장치로 볼 수 있다. 이를 hello 예제에 적용해보자. telnet을 이용하여 hello 프로그램을 다른 곳에 위치한 컴퓨터에서 실행할 수 있다. telnet 클라이언트를 사용하여 로컬 컴퓨터를 원격 컴퓨터의 telnet 서버와 연결하고 쉘 프로그램을 실행시킨다. “hello” 스트링을 telnet 클라이언트에 입력하고 엔터를 누르면 클라이언트는 이 스트링을 telnet 서버로 보낸다. telnet 서버가 네트워크에서 스트링을 받은 후, 원격 쉘 프로그램에 이를 전달한다. 다음으로 원격 쉘 프로그램이 hello 프로그램을 실행하고 출력을 telnet 서버로 전달한다면, 네트워크를 통해 다시 telnet 클라이언트로 전달하고 클ㅅ이다.라이언트 프로그램은 이를 로컬 터미널에 표시한다.
1.9 중요한 주제들
컴퓨터 시스템이란 단지 하드웨어 그 이상으로 응용프로그램의 실행이라는 궁극의 목적을 달성하기 위해 협ㄴ력해야 하는 하드웨어와 시스템 소프트웨어가 서로 연결된 것을 말한다.
1.9.1 Amdahl의 법칙
Gene Amdahl은 시스템의 일부 성능 개선의 효율성에 대해 간단하지만 직관적인 관찰을 하였다. 우리가 어떤 시스템의 한 부분의 성능을 개선할 때, 전체 시스템 성능에 대한 효과는 그 부분이 얼마나 중요한가와 이부분이 얼마나 빨라졌는지에 관계한다는 것이다.
T(new) = (1 - a)*T(old) + (a * T(old))/k = T(old)[ (1 - a) + a/k ]
- T(old) : 실행 시간
- a : 전체에서 이 부분이 걸리는 시간
- k : 성능을 높이려는 배수
여기에서 개선된 속도는 다음과 같이 구할 수 있다.
S = 1 / ((1 - a) + a/k)
1.9.2 동시 병렬성
- 동시성 : 시스템에서 다수의 동시에 벌어지는 것
- 병렬성 : 동시성을 사용해서 시스템을 보다 빠르게 동작하도록 하는 것
쓰레드 수준 동시성
- 단일 프로세서 시스템 : 쓰레드를 사용하여 하나의 프로세스 내에서 실행되는 다수의 제어흐름을 가지는 것
- 멀티 프로세서 시스템 : 여러 개의 프로세서를 가지고 하나의 운영체제 커널의 제어 하에 동작하는 경우
- 여러 개의 CPU 코어를 가진다.
- CPU 코어는 각각 L1, L2 캐시를 가진다.
- 각 CPU 코어는 메인 메모리 인터페이스와 상위 수준 캐시를 공유한다.
- 멀티쓰레딩 : 하나의 CPU가 여러 개의 제어 흐름을 실행할 수 있게 해주는 기술
- 매 사이클마다 실행할 쓰레드를 결정한다. 현재 쓰레드가 대기해야 한다면 다른 쓰레드를 실행시킨다.
인스트럭션 수준 병렬성
- 사이클당 한 개 이상의 인스트럭션을 실행할 수 있는 것을 말합니다.
싱글 인스트럭션, 다중 데이터 병렬성(SIMD)
- 한 개의 인스트럭션이 다수의 연산을 수행할 수 있는 특수 하드웨어를 가지는 것
- 영상, 소리, 동영상 데이터 처리를 위한 응용프로그램의 속도를 개선하기 위해 제공됩니다.
1.9.3 컴퓨터 시스템에서 추상화의 중요성
 추상화를 통해서 내부 동작을 고려하지 않으면서 코드를 사용할 수 있다.
추상화를 통해서 내부 동작을 고려하지 않으면서 코드를 사용할 수 있다.- 입출력 장치의 추상화 : 파일
- 프로그램 메모리의 추상화 : 가상 메모리
- 실행 중인 프로그램의 추상화 : 프로세스
- 운영체제, 프로세서, 프로그램 모두의 추상화 : 가상머신
1.10 요약
컴퓨터 시스템은 응용프로그램을 실행하기 위해 함께 동작하는 하드웨어와 시스템 소프트웨어로 구성된다. 컴퓨터 내의 정보는 상황에 따라 다르게 해석되는 비트들의 그룹으로 표시된다. 프로그램은 ASCII 문자로 시작해서 컴파일러와 링커에 의해 바이너리 실행파일로 번역되는 방식으로, 다른 프로그램들에 의해 다른 형태로 번역된다.
프로세서는 메인 메모리에 저장된 바이너리 인스트럭을 읽고 해석한다. 컴퓨터가 대부분의 시간을 메모리, 입출력장치, CPU 레지스터 간에 데이터를 복사하는 데 쓰고 있으므로 시스템의 저장장치들은 계층 구조를 형성하여 CPU 레지스터가 최상위에, 하드웨어 캐시 메모리, DRAM 메인 메모리, 디스크 저장장치 등이 순차적으로 위치한다. 계층 구조의 상부에 위치한 저장장치들은 하부의 장치들보다 비트당 단가가 더 비싸고, 더 빠르게 동작한다.
계층구조 상부의 저장장치들은 하부의 장치들을 위한 캐시 역할을 수행한다. 프로그래머들은 이러한 메모리 계층구조를 이해하고 활용해서 자신이 작성한 C 프로그램의 성능을 최적화할 수 있다.
운영체제 커널은 응용프로그램과 하드웨어 사이에서 중간자의 역할을 수행한다. 운영체제는 세 가지 근본적인 추상화를 제공한다 (1) 파일은 입출력장치의 추상화다. (2) 가상메모리는 메인 메모리와 디스크의 추상화다. (3) 프로세스는 프로세서, 메인 메모리, 입출력 장치의 추상화다.
끝으로 네트워크는 컴퓨터 시스템이 서로 통신할 수 있는 방법을 제공한다. 특정 시스템의 관점으로 볼 때, 네트워크는 단지 또 하나의 입출력장치다.
-
[면접질문] iOS 관련 질문
- Q. bound와 frame의 차이점을 설명하세요.
- Q. Foundation Kit은 무엇이고 어떤 클래스들이 포함되어있는지 설명하세요.
- Q. Cocoa Framework와 Cocoa Touch Framework의 차이는 무엇인가요?
- Q.두 개의 UIVIewController간 화면 전환이 이루어질 때의 시나리오를 UIVIewController life cycle과 관련해서 설명해주세요.
- Q.뷰의 위치나 크기를 재조정하려면 어떻게 해야하나요?
- Q. Delegate Pattern과 Notification의 동작 방식의 차이에 대해 설명하세요.
- Q. Code로 Autolayout을 작성할 수 있는 방법
- Q. Layer 가 무엇인가요?
안녕하세요! caution입니다. 면접 질문~ 두 번째~~ iOS 관련 질답을 대략적으로 정리해보고자 합니다. 간략하게 Q - A 정도로 작성할게요!
Q. bound와 frame의 차이점을 설명하세요.
bound와 frame 모두 해당 주체의 너비, 높이와 위치 좌표 값(x,y)를 나타냅니다. 다만 frame은 부모 뷰의 좌표시스템에서 자신의 위치를 나타내고, bound는 자신의 내부 좌표 시스템을 사용하여 위치를 나타냅니다. frame의 x, y 좌표를 변경하게 되면 자기 자신의 위치가 변경되지만 bound의 x,y 좌표를 변경하면 자신이 포함하는 하위 뷰들의 위치가 옮겨지게 됩니다.
Q. Foundation Kit은 무엇이고 어떤 클래스들이 포함되어있는지 설명하세요.
Foundation Kit은 Cocoa Touch framework에 포함되어 있는 프레임워크 중 하나입니다. String, Int 등의 원시 데이터 타입과 컬렉션 타입 및 운영체제 서비스를 사용해 앱의 기본적인 기능을 관리하는 프레임워크입니다.
Q. Cocoa Framework와 Cocoa Touch Framework의 차이는 무엇인가요?
Cocoa 는 Object-C 런타임을 기반으로 하고 NSObject를 상속받는 모든 클래스 또는 객체를 가리킵니다.
- Cocoa framework는 macOS를 개발할 때 사용합니다.
- Cocoa Touch Framework는 iOS 앱을 개발할 때 필수 프레임워크인 UIKit을 포함하며 iOS 개발에 필요한 Foundation, Coredata, MapKit, CoreAnimation 등을 포함합니다.
iOS 앱을 만들고 User Interface를 구성하는데 필수적인 프레임워크는 무엇인가요?
UIKit 입니다.
Q.두 개의 UIVIewController간 화면 전환이 이루어질 때의 시나리오를 UIVIewController life cycle과 관련해서 설명해주세요.
- UIVIewController A를 띄운다.
- loadView : viewController의 최상위 view를 로드합니다. 이 메소드를 override하면 기본 뷰를 교체할 수 있습니다. 만약 전체 뷰가 웹뷰여야 한다면 이 메소드에서 교체할 수 있겠죠!?
- viewDidLoad
- viewWillAppear
- viewDidAppear
- UIVIewController B로 화면을 이동한다.
- A.viewWillDisappear : 사라질꺼야
- B.viewDidLoad : 뷰 로드했어
- B.viewWillAppear : 뷰 보일 준비 됐어
- A.viewdidDisappear : 뷰 사라졌어
- B.viewDidAppear : 뷰 떴어!
사라질거야 > 로드했어 > 보일거야 > 사라졌어 > 보였다!
Q.뷰의 위치나 크기를 재조정하려면 어떻게 해야하나요?
viewWillLayoutSubviews()와 viewDidLayoutSubviews()
ViewController의 bounds가 변경되어 뷰의 서브 뷰의 위치를 재조정해야 할 때, 다음과 같은 순서로 메서드가 호출됩니다.
viewWillLayoutSubviews(): 뷰의 bounds가 변경되면, 뷰는 하위뷰의 레이아웃을 변경해야 하는데 그 작업을 하기전에 호출되는 메서드입니다.layoutSubViews(): 여기서 서브 뷰의 레이아웃을 조정해줍니다.viewDidLayoutSubviews(): 뷰의 bounds가 변경되면, 서브뷰들의 위치를 조정하고 나서 그 때 시스템이 이 메서드를 호출합니다. 그러나 일반적으로 서브뷰의 개별 레이아웃이 조정되기만 했을 때에는 호출되지 않습니다.
view의 위치나 크기를 조정해야 한다면
viewDidLayoutSubviews()에서 조정해야합니다. 왜냐하면layoutSubViews()가 호출되기 이전에는 frame과 bound가 정확하지 않기 때문입니다.그렇다면 뷰를 업데이트하기 위해서는 결론적으로
layoutSubViews()가 호출되게 해야하는데요, 이를 직접적으로 호출하면 안됩니다. 대신에 다음 Rendering Cycle에 다시 레이아웃해야한다는 것을 알려주기 위해서setNeedsLayout()메서드를 호출합니다. 만약 뷰의 레이아웃을 즉시 업데이트 해야 한다면layoutIfNeeded()를 사용합니다.setNeedsLayout()
layoutSubviews()예약하는 행위 중 가장 비용이 적게 드는 방법이setNeedsLayout()을 호출하는 것입니다. 이 메소드를 호출한 View는 재계산되어야 하는 View라고 수동으로 체크가 되며 update cycle에서layoutSubviews()가 호출되게 됩니다.이 메소드는 비동기적으로 작동하기 때문에 호출되고 바로 반환됩니다. 그리고 View의 보여지는 모습은 update cycle에 들어갔을 때 바뀌게 됩니다.
layoutIfNeeded()
이 메소드는
setNeedsLayout()과 같이 수동으로layoutSubviews()호출을 예약하는 행위이지만 update cycle이 올 때까지 기다리지 않고layoutSubviews()를 호출시키는 것이 아니라 그 즉시layoutSubviews()를 발동시키는 메소드입니다.만일 main run loop에서 하나의 View가
setNeedsLayout()을 호출하고 그 다음layoutIfNeeded()를 호출한다면layoutIfNeeded()는 그 즉시 View의 값이 재계산되고 화면에 반영하기 때문에setNeedsLayout()이 예약한layoutSubViews()메소드는 update cycle에서 반영해야할 변경된 값이 존재하지 않기 때문에 호출되지 않습니다(결론적으로 한 번만 호출됩니다).이러한 동작 원리로
layoutIfNeeded()그 즉시 값이 변경되어야 하는 애니매이션에서 많이 사용됩니다. 만일 setNeedsLayout을 사용한다면 애니매이션 블록에서 그 즉시 View의 값이 변경되는 것이 아니라 추후 update cycle에서 값이 반영되므로 값의 변경은 이루어지지만 애니매이션 효과는 볼 수 없는 것입니다.setNeedsLayout과 layoutIfNeeded의 차이점은 동기적으로 동작하느냐 비동기적으로 동작하느냐의 차이입니다.
Q. Delegate Pattern과 Notification의 동작 방식의 차이에 대해 설명하세요.
Delegate Pattern이란 필요한 동작들을 Protocol로 정의해 놓고, 어떤 작업이 필요할 때 위임자 인스턴스에게 protocol에 정의된 method들을 호출함으로써 작업을 위임하는 방식을 말합니다. 이 패턴의 장점은 위임자가 어떤 동작을 하는지, 혹은 위임자가 어떤 형태인지 알 필요 없이 그저 필요한 시점에 필요한 메소드를 호출하도록 설계함으로써 관심사를 분리할 수 있습니다. 예를 들어 흔히 사용하는 UITableView는 UITableViewDataSource protocol을 채택한 위임자를 가집니다. TableView를 그리기 위해 데이터가 필요하다면 UITableView는 Datasource 위임자에게 요청함 수 있습니다. 이러한 방식을 통해서 매번 UITableView를 커스텀할 필요 없이 같은 UITableView로 다른 모양과 다른 동작을 가지는 TableView를 구현할 수 있습니다.
Notification은 특정 이벤트가 발생했을 때 사전에 등록된 Notification 이름으로 알림이 발생했다는 것을 Notification Center에게 알려줍니다. 그럼 Notification Center는 해당 알림을 수신하겠다고 등록되어있는 곳에 다시 알려주는 방식입니다.
둘의 차이는 Delegate Pattern은 알림을 발생시키는 주체와 그에 대응하는 위임자가 1:1로 소통한다는 것이고, Notification은 1:N로 하나의 알림을 여러 주체가 받을 수 있습니다. 그렇기 때문에 Notification을 사용할 때 의도하지 않은 곳에서 알림을 수신하고 있는 지 주의해야합니다.
Q. Code로 Autolayout을 작성할 수 있는 방법
- Anchor를 사용한다.
thumbImageView.leftAnchor.constraint(equalTo: leftAnchor, constant: 5).isActive = true - NSLayoutConstraints를 사용한다.
NSLayoutConstraint(item: myView, attribute: .leading, relatedBy: .Equal, toItem: view, attribute: .leadingMargin, multiplier: 1.0, constant: 0.0).isActive = true - 비주얼 포맷 사용하기
let views = ["redView": redView, "blueView": blueView, "greenView": greenView] let format1 = "V:|-[redView]-8-[greenView]-|" let format2 = "H:|-[redView]-8-[blueView(==redView)]-|" let format3 = "H:|-[greenView]-|" var constraints = NSConstraint.constraints(withVisualFormat: format1, options: alignAllLeft, matrics: nil, views: views) constraints += NSConstraint.constraints(withVisualFormat: format2, options: alignAllTop, matrics: nil, views: views) constraints += NSConstraint.constraints(withVisualFormat: format3, options: [] matrics: nil, views: views) NSConstraint.activateConstraints(constraints)비주얼 포맷의 장점
- 오토레이아웃의 디버깅은 콘솔을 통해 비주얼 포맷을 사용하여 출력한다. 따라서 디버깅시에 사용되는 포맷과 생성에 사용하는 포맷이 일치한다.
- 비주얼 포맷을 사용하면 여러 제약 요소를 한 번에 만들 수 있다.
- 유효한 제약요소들만이 만들어진다. (단, 모든 필요한 제약요소가 다 만들어지는 것은 아니다.)
- 완전성보다는 좋은 시각화에 집중한 방식이다. 따라서 일부 제약요소는 이 방식으로 만들 수 없다.
- 단 포맷은 컴파일 타임에 체크할 수 없다. 실행하여 확인할 수만 있다.
Q. Layer 가 무엇인가요?
뷰는 이미지, 비디오, 글자들을 보여주는 객체이며 터치, 제스쳐 등의 이벤트를 받을 수 있습니다. (UIResponser) UIView는 렌더링, 레이아웃, 애니메이션 등을 관리하는 Core Animation Class인 CALayer가 있습니다. UIView와는 유사하지만 뷰의 비쥬얼적인 특성만을 가집니다. CALayer를 사용하면 shadow, rounded corner, colored border나 masking contents, Animation 등의 기능을 사용할 수 있습니다. 예를 들어 실제 뷰는 UIView이지만 layer단에 보여줄 image를 설정할 수 있습니다.
let image = UIImage(named: "temp") view.layer.contents = image.cgImageclipsToBounds() vs masksToBounds()
컨텐츠가 뷰의 크기를 벗어나지 않게 하기 위해서
view.clipsToBounds()를 사용합니다. 이와 비슷한 동작을 하는 메소드가 CALayer에는masksToBounds()입니다.만약 이미지는 rounded corner를 주고 싶고, 또 view의 shadow 효과도 주고 싶다면 어떻게 해야 할까요? layer는 view에 여러 곂으로 곂칠 수 있기 때문에, image를 rounded corner로 변경하고
masksToBounds()를 적용한 layer 하위에 shadow를 주는 layer를 추가하면 되지 않을까요?UIButton이 상속받는 것들

 UIControl과 NSCoding을 상속받는다.
UIControl은 UIView를 상속받는다.
UIControl과 NSCoding을 상속받는다.
UIControl은 UIView를 상속받는다.CGFloat과 Float의 차이
CGFloat는 CPU가 34bit 기반인지 64bit 기반인지에 따라 Float 혹은 Double입니다. Cocoa의 그래픽 API는 항상 CGFloat을 사용하기 때문에 그래픽 작업을 할 때에는 CGFloat을 사용해야 합니다. 그렇기 때문에 CGFloat으로 변환할 때에는 반드지 CGFloat(float), CGFloat(double)을 사용해야 합니다.
Array vs NSArray
Swift에서 Array는 구조체인 값 타입입니다. NSArray는 immutable한 Object-C 클래스로, Swift에서는 참조타입이며 Array
로 브릿징됩니다. NSMutableArray는 NSArray의 변경 가능한 하위 클래스입니다. 참조
-
[면접질문] Swift Q&A
- Q. Swift의 접근제어자(Access Control)는 어떤게 있나요?
- Q. defer 구문이 무엇인가요?
- Q. Struct와 Class의 차이는 무엇이고 어떤 때에 사용하나요?
- Q. Optional은 무엇이고, 왜 사용하나요?
- Q. method vs static method vs class method
- Q. 상속(inheritance)과 확장(extension)의 차이는 무엇일까요?
- Q. swift의 고차함수에는 무엇이 있나요?
- Q. Array, Dictionary, Set을 차이점에 기반하여 설명해 주세요.
안녕하세요! caution입니다. 오늘은 Swift 관련 면접 질문과 답을 대략적으로 정리해보고자 합니다. 간략하게 Q - A 정도로 작성할게요!
Q. Swift의 접근제어자(Access Control)는 어떤게 있나요?
키워드 범위 open 모듈 외부에서도 접근 가능 public 모듈 외부에서도 접근 가능 internal 하나의 모듈 내부에서 접근 가능 fileprivate 하나의 파일 내에서 접근 가능 private 정의 블록 내부에서 접근 가능 open과 public의 차이
open접근 수준을 가지는 클래스만이 모듈 밖의 다른 모듈에서 상속하고 멤버를 override할 수 있습니다.외부 프레임워크에서 모듈로 클래스를 가져와서써야되는데 접근제어자를 뭘 써야하나요?
가져올 수 있는 접근제어자에는 open과 public이 있습니다. 필요한 범위에 따라 불러오는 블록의 접근제어자를 지정해주면 됩니다. 단 public 으로 선언된 클래스 내부에서 open을 멤버로 선언할 수는 없습니다.
정리
- 바깥 요소의 접근제어 수준보다 높은 수준의 내부 요소는 있을 수 없다.
- 특정 접근제어 수준의 타입이 함수의 매개변수나 반환되는 타입일 경우 함수는 해당 값의 접근제어보다 높을 수 없다.
Q. defer 구문이 무엇인가요?
선언된 블럭의 코드 동작이 모두 수행되고 난 다음 블럭을 빠져나가기 전 마지막으로 불리는 영역입니다.
- defer 구문을 여러 개 선언하게 되면 선언된 역순으로 호출됩니다.
- 중첩해서 사용하면 바깥쪽 구문을 완료하고 내부의 defer 구문을 호출합니다.
func sample() { defer { print("1 start") defer { print("1-1 start") defer { print("1-1-1") } defer { print("1-1-2") } print("1-1 end") } print("1 end") } defer { print("2 start") defer { print("2-1") } defer { print("2-2") } print("2 end") } } sample()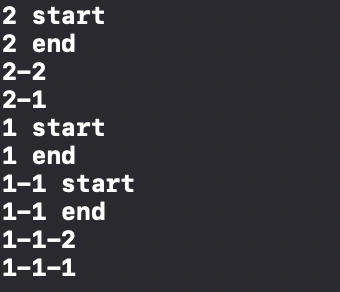
Q. Struct와 Class의 차이는 무엇이고 어떤 때에 사용하나요?
- struct는 값 타입, class는 참조 타입입니다.
- Reference Count를 높이지 않고, init/deinit 시 RC를 세지 않는다는 점. 즉 RC를 세는것도 하나의 작업이니깐 이 작업을 안하기 때문에 class에 비해 빠르다.
- 값 타입은 멀티스레딩에 안전하다.
- class보다 struct가 접근과 사용이 빠릅니다.
- struct는 Stack에, class는 Heap 영역에 저장됩니다.
- Stack 메모리 영역은 프로그램이 실행될 때 미리 영역을 확보해놓기 때문에 빈 공간을 확보할 필요 없이 데이터를 저장할 수 있습니다.
- 반면 Heap 영역은 필요할 때마다 동적으로 메모리를 할당해야하기 때문에 새로 들어올 데이터가 들어갈 수 있는 빈 공간이 있는지 탐색하고 없다면 공간을 할당해야한다.
- 하지만 인스턴스의 규모가 크면 struct보다는 class를 지향합니다.
- struct는 값 복사가 일어나기 때문에 데이터 양이 많다면 시간이 오래걸리기 때문입니다. 그에 비해 class는 참조 메모리 주소값만 복사하면 되서 다소 빠릅니다.
- struct는 상속을 받을 수 없지만 protocol은 채택가능하다.
Array와 Dictionary는 값 타입? 참조 타입?
Swift의 String과 Array, Set 등은 값 타입으로 되어있지만 내부는 참조 타입으로 되어있습니다. 그렇기 때문에 많은 양의 문자열을 복사해도 그 속도가 매우 빠릅니다.
Copy-on-write : 실제로 데이터가 수정(write)될 때 새로 메모리를 할당합니다. 값 타입 생성 속도 저하를 보완합니다.
Q. Optional은 무엇이고, 왜 사용하나요?
Optional은 nil을 넣을 수 있는 타입입니다. Swift는 안정성을 매우 중요시합니다. Optional을 사용하면 개발자가 놓칠 수 있는 부분을 보완할 수 있습니다. 특정 변수가 nil로 변환될 가능성이 있다면 Optional을 사용해서 옵셔널 바인딩을 통해
nilcase를 처리할 수 있습니다.Q. method vs static method vs class method
method는 class, struct, enum 등에 포함되어 있는 function을 말합니다. 우리가 일반적으로 말하는 class의 method에도 여러 종류가 있습니다.
class SuperClass { func instanceMehtod() {} static func staticMethod() {} class func classMethod() {} } class SubClass: SuperClass { override func staticMethod() {} override class func classMethod() {} }- instance method : class나 struct의 인스턴스를 통해서만 접근 가능한 method
- static method : 인스턴스 없이 직접 Class.Method 로 접근 가능한 method
- class method : static method와 동일하게 인스턴스 없이 접근 가능한 method이지만, class에서만 사용할 수 있으며 struct와 enum에서는 선언할 수 없습니다. 또한 static method와 달리 override가 가능합니다.
- protocol에서 class func 을 정의했다면 해당 프로토콜은 class만 채택가능하겠죠?
Q. 상속(inheritance)과 확장(extension)의 차이는 무엇일까요?
상속은 Swift에서 클래스를 다른 타입과 차별화 하는 기본 동작으로, 상속하는 클래스를 하위클래스, 상속 받은 클래스를 슈퍼클래스라고 합니다. 하위클래스는 슈퍼클래스에 속한 메소드, 프로퍼티 및 하위 스크립트들을 호출하고 접근할 수 있으며, 이를 재정의할 수 있습니다.
확장은 class, struct, enum 모두 사용할 수 있습니다. final로 선언된 class의 경우 상속이 불가능하지만 extension은 가능합니다. 상속은 수직계층적으로 범위를 넓히는 거라면 extension은 수평적으로 범위를 넓힌다고 볼 수 있습니다.
Q. swift의 고차함수에는 무엇이 있나요?
고차함수(Higher-order function)은 ‘다른 함수를 전달인자로 받거나 함수실행의 결과를 함수로 반환하는 함수’를 뜻합니다.
스위프트의 함수(클로저)는 일급시민이기 때문에 함수의 전달인자로 전달할 수 있으며, 함수의 결과값으로 반환할 수 있습니다.
map, filter, reduce
map함수는 컨테이너 내부의 기존 데이터를 변형(transform)하여 새로운 컨테이너를 생성합니다. filter함수는 컨테이너 내부의 값을 걸러서 새로운 컨테이너로 추출합니다. reduce함수는 컨테이너 내부의 콘텐츠를 하나로 통합합니다.
Q. Array, Dictionary, Set을 차이점에 기반하여 설명해 주세요.
세 개 모두 Swift에서 제공하는 컬렉션 타입입니다. Generic으로 특정 타입에 대한 컬렉션을 만들게 됩니다. Array는 순서가 있고 Dictionary와 Set은 순서가 없으며, Dictionary는 Hash 키-값을 연결한 Hash Table이고 Set은 중복값을 허용하지 않습니다. 중복값을 허용하지 않기 위해서 Set에 들어갈 수 있는 값들은 Hashable 자료형입니다.
Hash Table에서 Hash는 왜 사용하나요? Hash 함수의 성능이 떨어진다면 어떤 문제가 발생할 수 있나요?
Hash를 사용하는 이유는 데이터를 접근할 때 O(1)으로 한 번에 접근하기 위해서입니다. 이 Hash 값을 만들어 내는 함수를 Hash 함수라고 하는데 이 함수는 같은 입력값에는 같은 출력값을 나타내고, 출력값으로는 입력값을 유추할 수 없는 특징을 가집니다. 하지만 Hash 함수를 사용하더라도 충돌이 발생하게 됩니다. 서로 다른 입력값에 같은 키를 만들어 내게 된다면 어떻게 될까요? 해시 테이블에서는 키에 해당하는 공간을 연결 리스트로 만들어 넣게 됩니다. 만약 최악의 경우 이렇게 항목들이 연결 리스트로 들어가 있다면 데이터를 가져오기 위해 O(n)의 시간이 걸리게 됩니다.
case Hash Table 평균 Hash Table 최악 배열 Linked List 탐색 O(1) O(n) O(1) O(n) 삽입 O(1) O(n) O(n) O(1) 삭제 O(1) O(n) O(n) O(1)
-
Strong Weak 참조
안녕하세요! caution입니다. 혹시 값 타입과 참조 타입의 차이를 아시나요? 아니면 swift의 class와 struct의 차이를 아시나요?(모르겠다면 클릭) 오늘 우리가 말하려고 하는 건 참조 타입 객체를 사용할 때 강한 참조, 약한 참조 중 어떤 걸 써야하는지에 대한 이야기입니다.
먼저 예를 들어보겠습니다. 부모(Parent)와 자식(Child) 클래스가 있다고 생각해보겠습니다.
class Parent { let name: String init(name: String) { self.name = name } var child: Child? } class Child { let name: String var parent: Parent? init(name: String, parent: Parent) { self.name = name self.parent = parent } }부모는 자식을 가지고, 자식은 부모를 가질 수 있죠. 하지만 안타깝게도 부모와 자식 모두 서로를 상실(?)할 수 있기 때문에 optional type으로 선언했습니다. 그럼 이제 부모와 자식을 만들어고 연결해줍시다.
var parent: Parent? = Parent(name: "가상부모") var child: Child? = Child(name: "가상아이", parent: parent) parent.child = child자 이 작업을 자세히 살펴봅시다. 첫 번째 줄에서 Parent 인스턴스를 만들었고, parent가 이 인스턴스를 참조하게 만들었습니다. 이때 Parent 인스턴스 대한 Reference Count 가 1로 올라갑니다. 두 번째 줄에서 Child 객체를 만들었고 child가 참조하고 있으니 마찬가지로 Child 객체의 Reference count는 1로 올라갑니다.
하지만 주의해야할 것은 Child 인스턴스를 초기화하면서 parent 인스턴스 프로버티가 Parent 인스턴스를 참조하도록 설정해주었다는 것입니다. 이 작업을 통해서 Parent 인스턴스를 Reference Count는 2로 올라갑니다. 그리고 세 번째 줄에서 다시 한 번 Parent 인스턴스의 child 프로퍼티에 방금 생성한 Child 인스턴스를 참조하도록 합니다. 이를 통해 Child의 Reference count 또한 2로 올라갑니다.
우리가 참조할 때에 weak나 unowned와 같은 참조타입을 명시해주지 않았기 때문에 이 두 인스턴스는 기본적으로 서로를 strong 하게 참조하고 있습니다.
이 상태에서, 우리가 선언했던 parent 와 child를 모두 nil로 바꾸면 어떻게 될까요?
parent = nil child = nil일단 변수 parent, child 에서 인스턴스에 대한 참조가 해제되었습니다. 그래서 Parent와 Child는 사실상 논리적으로는 아무도 참조하고 있지 않기 때문에 메모리 해제가 이루어져야하지만, Reference count가 2에서 1로 떨어졌기 때문에 여전히 1이 남아있어 ARC에 의한 해제가 발생하지 않습니다. 두 인스턴스가 서로를 강하게 참조하고 있기 때문이죠. 둘 중 어떤 것을 해제하려고 하더라도 다른 것에서 참조하고 있다고 인식되게 됩니다.
이 문제를 해결하려면 어떻게 해야할까요?
강한 참조, 약한 참조, 미소유 참조
참조 타입을 참조하는 방식에는 3가지가 있습니다. strong, weak, unowned 기본적으로 프로퍼티를 선언할 때 weak 나 unowned를 선언하지 않으면 기본 값은 strong입니다. weak와 unowned는 약한 참조로 참조가 일어나더라도 Reference Count를 증가시키지 않습니다.
앞선 class들을 다시 변경해봅시다.
class Parent { let name: String var child: Child? init(name: String) { self.name = name } } class Child { let name: String weak var parent: Parent? init(name: String, parent: Parent) { self.name = name self.parent = parent } }Child의 parent 프로퍼티를 weak 로 선언해주었습니다. 이렇게 weak 참조로 변하게 되면, 참조하고 있는 인스턴스가 메모리 해제를 시도하려고 할 때(nil 로 변환될 때), 이 값은 자동으로 nil로 변하게 됩니다. 즉 메모리 해제를 방해하지 않습니다. 그렇기 때문에 약한 참조방식은 상수(let)이 아닌 변수(var)에서만 가능하며, nil로 변할 수 있기에 optional 타입만 허용됩니다.
그렇다면 왜 모든 변수를 weak로 선언하지 않나요?
class는 참조 타입입니다. 여러 변수가 하나의 인스턴스를 참조하고 있을 수 있습니다. 만약 모든 변수가 weak로 설정되어 있다면, 어느 한 변수에서 nil로 변환되거나 ARC에 의해서 메모리 해제가 발생했을 때, 의도치 않게 다른 참조 또한 nil로 변할 수 있습니다.
모든 참조를 약한 참조로 변경했습니다.
class Parent { let name: String weak var child: Child? init(name: String) { self.name = name } } class Child { let name: String weak var parent: Parent? init(name: String, parent: Parent?) { self.name = name self.parent = parent } }코드를 조금 변경해보죠. Child를 변수에 참조시키지 않고 바로 Parent의 프로퍼티에 담아보겠습니다.
let parent: Parent? = Parent(name: "가상부모") parent?.child = Child(name: "가상아이", parent: parent) print(parent?.child?.name)결과는 어떨까요? Child 인스턴스가 잘 살아있다면
가상아이가 나타나야 하겠지만 결과는nil이 나옵니다. 왜 그럴까요? Xcode에서 이 코드를 작성하게 되면 다음과 같은 오류를 발생시킵니다.Instance will be immediately deallocated because property ‘child’ is ‘weak’
약한 참조는 Reference count 를 증가시키지 않습니다. 그렇기 때문에 Child 인스턴스가 만들어졌지만 RC가 0이기 때문에 언제든지 ARC에 의해서 dealloc될 수 있습니다.
위의 문제를 해결하려면 어떻게 해야할까요? 간단합니다. Parent의 child property를 강한 참조로 변경해주면 문제가 해결됩니다. 강한 참조가 약한 참조보다 나쁘다는 것이 아니라, 순환참조를 해결하기 위해 약한 참조를 사용합니다.
그럼 unowned는 뭔가요?
마찬가지로 RC를 증가시키지 않는 참조법이지만, Optional 타입이 아닐 때 사용할 수 있습니다. 주의해야할 점은 메모리 해제가 이루어진 뒤 미소유 참조에 그대로 접근하게 되면 런타임 에러가 발생할 수 있습니다.
따라서 unowned를 사용할 때에는 이 값이 nil인지 아닌지를 체크해서 사용해야 합니다.
###자동 참조 계수(Automatic Reference Counting) Swift는 앱의 메모리 사용을 추적하고 관리하는 자동 참조 계수(ARC)를 사용. 대부분의 경우에 메모리 작업은 잘 작동하며, 메모리 관리를 생각할 필요 없다. ARC는 인스턴스가 더이상 필요가 없을 때 클래스 인스턴스에 사용된 메모리를 자동적으로 해제한다.
몇가지 경우에 ARC는 메모리 순서에서 코드 부분들의 사이 관계에 대한 더 많은 정보가 필요하다.
참조 계수는 클래스의 인스턴스에만 적용되며, 구조체와 열거형은 값 타입이지 참조 타입이 아니며 참조를 저장 못하고 넘기지 못한다.
ARC 작업 방법(How ARC Works)
매시간 클래스의 새로운 인스턴스를 만들며, ARC는 인스턴스에 대한 정보를 메모리 덩어리에 저장하기 위해 할당한다. 메모리는 인스턴스의 타입 정보와 저장 속성에 할당된 인스턴스 값을 쥔다.
게다가 인스턴스가 더이상 필요가 없으면 ARC는 인스턴스에 사용된 메모리를 해제하고 메모리는 다른 목적을 위해 사용되어진다. 더 이상 필요가 없을 때 메모리에는 클래스 인스턴스가 공간을 차지하지 않는다는 확신한다.
그러나 ARC는 사용중에 인스턴스를 할당 해제하면 인스턴스의 속성 접근이나 인스턴스 메소드 호출이 더이상 가능하지 않다. 대신에 인스턴스를 접근하려고 하면, 앱은 크래쉬가 날 수 있다.
인스턴스가 필요한 동안에는 사라지지 않게 하기 위해선, ARC는 많은 속성, 상수 그리고 변수가 현재 각 클래스 인스턴스를 참조하기 위해 추적한다. ARC는 적어도 하나의 활성화 참조가 있는 이상 인스턴스는 할당 해제되지 않고 계속 존재한다.
속성, 상수 또는 변수에 클래스 인스턴스를 할당할 때, 속성, 상수 또는 변수는 인스턴스에 강한 참조를 만든다. “강한” 참조는 인스턴스르 강하게 유지하며, 강한 참조가 남아있다면 해당 인스턴스를 할당 해제하지 못한다.
참조