Welcome to caution's Blog!
안녕하세요, iOS 개발자 김주희입니다.-
GCD vs Operation Queue
동시성 프로그래밍과 비동기 프로그래밍
프로세서
컴퓨터 내에서 프로그램을 수행하는 하드웨어 유닛으로 CPU (Central Processing Unit)이 여기에 속합니다. 한 컴퓨터가 여러 개의 프로세서를 갖는다면 멀티 프로세서라고 합니다. (듀얼 프로세서 등)
코어
프로세서 내부의 주요 연산회로를 말합니다. 싱글코어는 하나의 연산회로가 내장되어 있는 것이고 듀얼코어는 두 개의 연산회로가 내장된 것을 말합니다.
프로그램과 프로세스
프로그램은 보조기억 장치에 저장된 실행코드를 말합니다. 프로세스는 이 프로그램을 구동하여 실행코드와 그 상태가 실제 메모리상에서 실행되는 작업 단위를 말합니다. 동시에 여러 개의 프로세스를 운용하는 시분할 방식 을 멀티태스킹이라고 합니다. 이러한 프로세스 관리는 운영체제에서 담당합니다.
스레드
스레드는 하나의 프로세스 내에서 실행되는 작업흐름의 단위를 말합니다. 보통 한 프로세스는 하나의 스레드를 가지고 있지만 환경에 따라 둘 이상의 스레드를 동시에 실행할 수 있습니다. 이러한 방식을 멀티스레딩이라고 합니다. 프로그램 실행이 시작될 때부터 동작하는 스레드를 메인 스레드라고 하고 나중에 생성된 스레드를 서브 스레드 또는 세컨더리 스레드라고 합니다.
비동기 프로그래밍
프로그램의 주 실행 흐름을 멈추어서 기다리지 않고 다음 작업을 실행할 수 있게 하는 방식입니다. 코드의 실행 및 결과 처리를 별도의 공간에 맡겨둔 뒤 그 실행결과를 기다리지 않고 다음 코드를 실행하는 병렬처리 방식입니다. 비동기 프로그래밍은 언어 및 프레임워크에서 지원하는 여러 방법으로 구현할 수 있습니다.
동시성 프로그래밍
논리적인 용어로 동시에 실행되는 것처럼 보이는 방식입니다. 싱글 코어에서 멀티스레드를 동작시키기 위한 방식으로 멀티 태스킹을 위해 여러 개의 스래드가 번갈아 가면서 실행되는 방식입니다.
병렬성 프로그래밍
물리적으로 정확히 동시에 실행되는 것을 말합니다. 멀티 코어에서 멀티 스레드를 동작시키는 방식으로 데이터 병렬성(Data Parallelism)과 작업 병렬성(Task Parallelism)으로 구분됩니다.
- 데이터 병렬성 : 전체 데이터를 나누어 서브 데이터들로 만든 뒤, 서브 데이터들을 병렬 처리해서 작업을 빠르게 수행하는 방법입니다.
- 작업 병렬성 : 서로 다른 작업을 병렬 처리하는 것을 말합니다.
동시성과 병렬성의 차이
동시성 프로그래밍과 병렬성 프로그래밍 모두 비동기 동작을 구현할 수 있지만 동작 원리가 다릅니다.
예를 들어 꼬치 가게에서 꼬치를 사려고 기다리고 있다고 생각해봅시다. 꼬치 가게 판매 직원이 2명이어서 사람들은 줄을 2줄로 섰습니다. 그래서 판매직원 한명이 한 줄을 담당해서 N:N으로 업무처리를 진행하는 게 됩니다. 이게 병렬성 입니다. 병렬성은 물리적으로 동시에 여러 작업을 처리할 수 있습니다. 판매직원이 하나의 코어 가 되고, 줄이 처리해야하는 데이터나 작업인 것이죠. 이 병렬성을 구현하기 위해서는 멀티 코어 환경이 필요합니다.
그렇다면 이 상황에서 판매 직원 하나가 급히 자리를 비운다면 어떻게 될까요? 한 줄만 계속해서 판매된다면 다른 줄의 사람들의 원성을 사게 되겠죠. 그래서 한 명의 판매직원이 두 줄의 손님을 번갈아가면서 판매합니다. 논리적으로는 하나의 코어가 여러 줄의 작업을 동시에 처리하는 것처럼 보이지만 물리적으로 동시에 처리하는 것은 아닙니다.
iOS 환경에서의 동시성 프로그래밍 지원 종류
- GCD (Grand Central Dispatch) : 멀티 코어와 멀티 프로세싱 환경에서 최적화된 프로그래밍을 할 수 있도록 애플이 개발한 기술입니다.
- Operation Queue : 비동기적으로 실행되어야 하는 작업을 객체 지향적인 방법으로 사용합니다.
-
iOS Application state
Applicsation state
iOS 에서 앱은 5 가지의 상태로 구분이 가능하며 항상 하나의 상태를 가지고 있습니다.
- Not Running : 앱이 실행되지 않았거나, 시스템에서 종료되었습니다.
- In-Active : 앱이 Foreground에서 실행중이지만, 이벤트를 받을 수 없습니다. 대개 이 상태에 잠시 머물렀다가 다른 상태로 전이됩니다.
- Active : 일반적으로 앱이 화면에 떠 있을 때의 상태입니다. 이벤트를 받을 수 있습니다.
- Background : 앱이 백그라운드에서 코드를 실행하고 있습니다. 대부분의 앱은 일시 중지 상태로 잠시 이 상태가됩니다. 그러나 추가 실행 시간을 요청하는 앱은 일정 기간 동안 이 상태로 남아있을 수 있습니다. 또한 백그라운드로 직접 실행되는 앱은 비활성 상태 대신 이 상태로 전환됩니다.
- Suspended : 앱이 백그라운드에 있지만 코드를 실행하지 않습니다. 시스템은 앱을 자동으로 이 상태로 이동시키고 그렇게하기 전에 앱에 알리지 않습니다. 일시 중지 된 앱은 메모리에 남아 있지만 코드는 실행하지 않습니다. 메모리 부족 상태가 발생하면 시스템은 예고없이 일시 중단 된 앱을 제거하여 메모리를 확보합니다.

상태전이
사용자의 동작에 따라 앱의 상태가 변경됩니다.
- 시나리오 1. 사용자가 앱을 실행합니다.
- Not Running » In-Active » Active
- 시나리오 2. 앱 실행 도중 홈 버튼을 누릅니다.
- Active » In-Active » Background
- 시나리오 3. 앱을 다시 켭니다.
- Background » Active
- 시나리오 4. 앱이 백그라운드에 있다가 Suspended 상태로 전이됩니다.
- Active » In-Active » Background » Suspended
상태 변화에 따라 다른 동작을 처리하기 위한 Delegate 메서드
- application:willFinishLaunchingWithOptions: 앱 런칭이 끝나기 전 불리는 메소드로, 앱 런칭 타임에서 코드를 실행할 수 있는 첫 번째 시점입니다.
- application:didFinishLaunchingWithOptions : 앱 런칭 시점에서 Application 단의 초기화 작업등을 수행할 수 있습니다.
- applicationDidBecomeActive : Active 상태로 전이 될 때 호출됩니다. Background 상태의 앱이 다시 호출되어 Active 상태가 되도 호출됩니다.
- applicationWillResignActive : 앱이 Active 상태를 벗어나기 전에 호출됩니다. (ex. 홈 버튼을 누르면 호출됨) 단, 앱이 Background 상태로 전이된다는 보장은 없습니다. In-Active에 잠깐 머물다가 다시 바로 Active 상태로 바뀔 수도 있습니다.
- applicationDidEnterBackground : Background로 진입 후 호출됩니다. 언제든 System에 의해 Suspended 상태로 전이될 수 있으므로 나중에 재생성할 수 있는 모든 리소스들을 제거하고 사용자 데이터를 저장한는 등의 작업을 수행하는 용도로 사용할 수 있다. 이 메소드 호출 이전에 applicationWillResignActive가 호출됩니다.
- applicationWillEnterForeground : Background를 벗어나 Foreground로 진입될 것을 알려준다. (아직 Active 상태는 아님) applicationDidEnterBackground 에서 해제한 리소드들을 재생성하는 용도로 사용할 수 있습니다. 이 메소드 호출 뒤에 applicationDidBecomeActive 가 호출됩니다.
- applicationWillTerminate : 앱이 종료될 것임을 알려줍니다. 앱이 Suspended 상태에서 종료되는 것이라면 호출되지 않는다.
앞 선 시나리오 적용
-
시나리오 1. 사용자가 앱을 실행합니다.
- Not Running
- In-Active
- application:willFinishLaunchingWithOptions
- application:didFinishLaunchingWithOptions
- Active
- applicationDidBecomeActive
-
시나리오 2. 앱 실행 도중 홈 버튼을 누릅니다.
- Active
- applicationWillResignActive
- In-Active » Background
- applicationDidEnterBackground
- Active
-
시나리오 3. 앱을 다시 켭니다.
- Background
- applicationWillEnterForeground
- Active
- applicationDidBecomeActive
- Background
-
시나리오 4. 앱이 백그라운드에 있다가 Suspended 상태로 전이됩니다.
- Active
- applicationWillResignActive
- In-Active » Background
- applicationDidEnterBackground
- Suspended
- Active
Backgound 상태에서 할 수 있는 작업
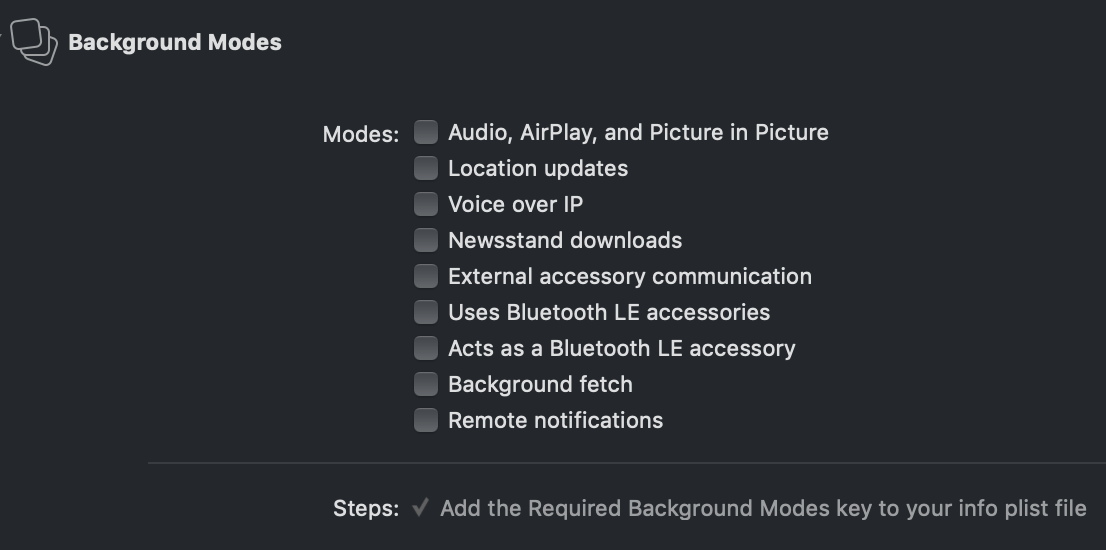
Xcode background Mode UIBackgroundModes 값 설명 Audio and AirPlay audio 백그라운드에서 들을 수 있는 컨텐츠를 재생하거나 오디오를 녹음합니다. (이 콘텐츠에는 AirPlay를 사용하여 스트리밍 오디오 또는 비디오 콘텐츠가 포함됩니다.) 사용자는 앱을 처음 사용하기 전에 마이크를 사용할 수있는 권한을 부여해야합니다. Location updates location 백그라운드에서 실행 중에도 사용자의 위치 정보를 제공받습니다. Voice ove IP voip 인터넷 연결을 사용해서 전화할 수 있도록 합니다. Newsstand downloads newsstand-content 백그라운드에서 잡지나 뉴스들을 다운로드할 수 있는 앱입니다. External accessory communication external-accessory 외부 엑서서리 프레임워크를 통해 정기적인 일정으로 업데이트를 제공해야 하는 하드웨어 액서서리와 함께 동작합니다. Uses Bluetooth LE accessories bluetooth-central Core Blutooth 프레임워크를 통해 정기적 업데이트를 제공해야 하는 블루투스 액서서리와 함께 동작합니다. Acts as a Bluetooth LE accessory bluetooth-peripheral 이 앱은 Core Blutooth 프레임워크를 통해 주변 장치 모드에서 Blutooth 통신을 지원합니다. 사용자 궈한이 필요합니다. Background fetch fetch 앱은 정지적으로 네트워크에서 소량의 데이터를 다운로드하고 처리합니다. Remote notifications remote-notification 푸쉬 알림이 도착하면 앱에서 콘텐츠 다운로드를 시작하려고 합니다. 이 알림을 사용하여 푸쉬 알림과 관련된 콘텐츠 표시의 지연을 최소화하십니오. Background 에서 작업하고자 할 때 사용되는 함수
beginBackgroundTask(expirationHandler:)
새로운 장기 실행 백그라운드 작업을 시작한다고 표시합니다.
- handler : background 시간이 0에 도달했을 때 불리는 핸들러로 백그라운드 작업의 종료를 정리하고 표시합니다. 작업을 명시적으로 종료하지 않으면 앱이 강제종료됩니다. 시스템이 일시적으로 앱이 suspend 상태에 들어가지 않도록 차단합니다.
- return : 새 백그라운드 작업의 고유 식별자입니다. 이 작업의 끝을 표시하려면이 값을 endBackgroundTask : 메서드에 전달해야합니다. 이 메소드는 백그라운드에서 실행이 불가능한 경우 UIBackgroundTaskInvalid를 리턴합니다.
beginBackgroundTask(withName:expirationHandler:)
특정 이름을 부여한 새로운 장기 실행 백그라운드 작업을 시작한다고 표시합니다.
- taskName : 백그라운드 작업을 볼 때 디버거에 표시 할 이름입니다. nil이 매개 변수 를 지정하면 이 메서드는 호출하는 함수 또는 메서드의 이름을 기반으로 이름을 생성합니다.
- handler : 앱의 남은 배경 시간이 0에 도달하기 직전에 호출되는 핸들러. 이 핸들러를 사용하여 백그라운드 태스크의 끝을 정리하고 표시합니다. 작업을 명시 적으로 종료하지 않으면 앱이 종료됩니다. 시스템은 메인 스레드에서 동 기적으로 핸들러를 호출하여 일시적으로 앱의 일시 중단을 차단합니다.
- return : 새 백그라운드 작업의 고유 식별자입니다. 이 작업의 끝을 표시하려면이 값을 endBackgroundTask : 메서드에 전달해야합니다. 이 메소드는 백그라운드에서 실행이 불가능한 경우 UIBackgroundTaskInvalid를 리턴합니다.
이 메소드들은 앱의 백그라운드 실행 시간을 추가로 요청합니다. 미완성된 작업을 떠날 때 이 메소드를 호출하면 앱의 사용자 환경에 해로울 수 있습니다. 예를 들어, 작업이 진행되는 동안 시스템이 앱을 일시 중지하지 못하도록 데이터를 파일에 기록하기 전에 이 메서드를 호출하십시오. 백그라운드로 이동 한 후에 앱을 계속 실행하는 데 이 메소드를 사용하지 마십시오.
작업을 시작하기 전에 가능한 한 빨리 이 메서드를 호출하십시오. 응용 프로그램이 실제로 백그라운드에 들어가기 전에 수행하는 것이 좋습니다. 메서드는 비동기적으로 앱에 대한 작업 assertion을 요청합니다. 앱이 일시 중지되기 직전에 이 메소드를 호출하면 작업 어설션이 승인되기 전에 시스템이 앱을 일시 중지 할 수 있습니다. 예를 들어, applicationDidEnterBackground : 메서드 끝에서 이 메서드를 호출하지 말고, 앱이 계속 실행될 것으로 기대하십시오. 시스템이 작업 assertion을 부여 할 수 없으면 만기 핸들러를 호출합니다.
endBackgroundTask(_:)
특정 백그라운드 작업이 끝날 것임을 표시합니다.
참고
-
자료구조의 시작
안녕하세요, caution입니다.
부스트캠프도 끝났고 일본여행도 갔다왔겠다 할 일 없는 백수는 오늘부터 자료구조 공부를 시작합니다.
책은 파이썬과 함께하는 자료구조의 이해 를 선택했습니다. 그 이유는 파이썬 코드가 의사코드와 유사해서 자료구조와 알고리즘을 익히는데 도움이 될 것이라고 생각해서입니다.
비교적 얇은 책이니 후루룩 읽고 후루룩 흡수해보겠습니다.
그럼 시작합니다!
01 자료구조를 배우기 위한 준비
1.1 자료구조와 추상데이터 타입
Q. 자료구조 란?
A. 일련의 동일한 타입의 데이터를 정돈하여 저장한 구성체
Q. 왜 데이터를 정돈하는가?
A. 프로그램에서 저장하는 데이터에 대해 탐색, 삽입, 삭제 등의 연산을 효율적으로 수행하기 위해서 이다. 그래서 자료구조를 설계할 때에는 데이터와 관련된 연산들을 고려하여 설계해야 한다.
Q. 추상데이터 타입 ?
A. Abstract Data Type : 데이터와 데이터에 대한 추상적인 연산들의 관계를 나타내는 개념. 추상적이기 때문에 구체적으로 구현되는 방식을 적은 것은 아니다. 자료구조는 이를 실제 프로그램으로 구현한 것을 의미한다.
자주 사용되는 자료구조로는 리스트, 연결리스트, 스택, 큐, 트리, 해시테이블, 그래프 등이 있으며 이를 사용하여 특정 문제를 해결하기 위한 알고리즘 을 설계할 수 있다. 이를 위해서는 데이터 X 연산 의 관계를 개념적으로 정립하는 추상데이터 타입을 만들고 이를 기반으로 자료구조를 만들어야 효율적인 알고리즘의 설계가 가능하다.
추상 데이터 타입 -> 자료구조 -> 알고리즘
1.2 수행시간의 분석
Q. 자료구조의 효율성은 어떻게 측정할 수 있을까?
A. 연산의 수행시간으로 효율성을 측정할 수 있다. 이는 알고리즘의 성능을 측정하는 방식과 동일하다.
- 시간복잡도 : 알고리즘이 실행되는 동안에 사용된 기본적인 연산 횟수를 나타낸다.
- 공간복잡도 : 알고리즘이 수행되는 동안 사용되는 메모리 공간의 크기를 나타낸다.
대부분의 경우 시간복잡도를 사용하여 효율성을 측정한다. 그 이유는 주어진 문제를 해결하기 위한 대부분의 알고리즘이 비슷한 크기의 메모리 공간을 사용하기 때문이다.
Q. 왜 실제 측정된 시간이 아니라 횟수로 시간 복잡도를 계산하는가?
A. 실제 측정된 시간으로는 객관적으로 평가하는데에 그 한계가 있다. 사용되는 언어, 컴퓨터의 성능 등 얼마든지 달라질 수 있기 때문이다.
시간복잡도 분석 방법
- 최악경우 분석 : 어떤 입력이 주어지더라도 수행시간은 이 이상을 넘지 않는다.
- 평균경우 분석 : 입력이 무작위로 주어진다고 가정했을 때(균등분포)의 평균 시간
- 최선경우 분석 : 가장 빠른 수행시간을 분석하는 것으로 최적 알고리즘 을 찾는데 활용한다.
출퇴근을 한다고 가정했을 때, 지하철역까지는 5분, 지하철을 타면 회사까지 20분, 엘리베이터를 타고 사무실 까지 가는데 5분이 걸린다.
최선 경우는 집을 나와서 바로 지하철을 타고 바로 엘리베이터를 탔을 때 30분이 걸리는 경우이다. 최악경우는 지하철을 눈 앞에서 놓치고, 엘리베이터에 사람이 너무 많아서 다음 엘리베이터를 기다려야 하는 경우이다. 지하철 배차가 5분이고, 엘리베이터를 타는데 추가로 5분이 소요되었다면 최악경우는 10분이 추가된 40분이다. 평균시간은 최선과 최악의 중간으로 가정했을 때 35분이 된다.
흔히들 “회사에 지각하지 않으려면 늦어도 40분 전에는 출발해야 한다.”라고 최악의 경우를 말하는 것처럼, 알고리즘의 수행시간도 대부분 최악 경우로 표현한다.
1.3 수행시간의 점근표기법
수행시간 : 입력크기(N)이 주어졌을 때 알고리즘이 수행하는 기본 연산 횟수
이는 대부분 다항식으로 표현될 수 있으며 이 다항식을 다시 함수로 표현하기 위해서 점금표기법 이 사용된다.
대표적인 점근 표기법
- O : Big-Oh 표기법
- Ω : Big-Omega 표기법
- 𝛩 : Theta 표기법
Big-Oh(O) 표기법
c > 0 이며, 모든 N > N₀에 대해서 f(N) ≤ c*g(N) 이 성립하면 f(N) = O(g(N)) 이다.
O-표기가 나타내는 수행시간은 상한시간, 즉 최악 경우를 나타낸다.
EX) 어떤 알고리즘의 수행시간이 2N² + 3N + 5 라면?
- 양의 상수 c = 4
- g(N) = N²
- 모든 N에 대해 2N² + 3N + 5 ≤ 4N² 이 성립한다.
- 따라서 2N² + 3N + 5 ≤ O(N²)
양의 상수 c를 정할 때 그 값을 만족하는 가장 작은 값을 구하려하지 않아도 된다. 상수가 얼마냐가 중요한 것이 아니라, f(N) ≤ c * g(N) 을 성립하는 양의 상수이기만 하면 된다.
물론 2N² + 3N + 5 ≤ O(N³) 도 성립하고, 2N² + 3N + 5 ≤ O(2ᴺ) 도 성립하지만 가장 차수가 낮은 함수를 선택하는 것이 바람직하다.
앞선 예에서 출퇴근 시간은 최대 40분 소요되는데, 이를 “100시간 내로는 간다.”도 맞는 말이고 “10시간은 안 걸린다.”도 맞는 말이지만, “1시간 넘게는 안 걸린다.”가 더욱 정확한 표현이기 때문이다.
O-표기를 찾기 위해 직접 양의 상수 c 와 N₀를 계산해서 g(N)을 찾을 수도 있지만, 간단하게는 다항식에서 최고 차수 항만을 취한뒤 그 항의 계수를 제거하여 g(N)을 정하면 된다.
Big-Omega(Ω) 표기법
c > 0 이며, 모든 N > N₀ 에 대해서 f(N) ≥ c*g(N) 이 성립하면 f(N) = Ω(g(N)) 이다.
와. O-표기법과 비교연산자의 방향만 바뀌었다. O-표기법은 최악의 경우를 나타내고, Ω-표기법은 최선의 경우(하한)를 나타내는 걸 알 수 있다. 마찬가지로 양의 상수 c의 값은 중요하지 않고 최고 차수 항만을 취하여 g(N)을 정할 수 있다.
EX) 어떤 알고리즘의 수행시간이 2N² + 3N + 5 라면?
- 양의 상수 c = 1
- g(N) = N²
- 모든 N에 대해 2N² + 3N + 5 ≥ N² 이 성립한다.
- 따라서 2N² + 3N + 5 ≥ Ω(N²)
마찬가지로 정확한 표현을 나타내기 위해서 g(N)을 선택할 때에는 정의를 만족하는 가장 높은 차수의 함수를 선택하는 것이 바람직하다. 2N² + 3N + 5 ≥ 0 또한 성립하고, 2N² + 3N + 5 ≥ Ω(N) 또한 성립하지만 2N² + 3N + 5 ≥ Ω(N²)을 선택하는 것이 좋다.
Theta(𝛩) 표기법
c₁, c₂ > 0 이며, 모든 N > N₀ 에 대해서 c₁g(N) ≥ f(N) ≥ c₂g(N) 이 성립하면 f(N) = 𝛩(g(N)) 이다.
𝛩-표기는 수행시간의 O-표기와 Ω-표기가 동일한 경우에 사용한다. 앞선 예에서 알고리즘의 수행시간은 2N² + 3N + 5 였는데, O(N²), Ω(N²)이므로 𝛩(N²) 이다. 이는 곳 이 알고리즘의 수행시간이 N²과 유사한 증가율을 가지고 있다는 뜻이다.
자주 사용되는 O-표기
알고리즘의 수행시간은 주로 O-표기를 사용하며, 보다 정확한 표현을 위해서 𝛩-표기를 사용하기도 한다.
O-표기 이름 O(1) 상수 시간 O(logN) 로그 시간 O(N) 선형 시간 O(NlogN) 로그선형시간 O(N²) 제곱 시간 O(N³) 세제곱 시간 O(2ᴺ) 지수 시간 O(1) < O(logN) < O(N) < O(NlogN) < O(N²) < O(N³) < O(Nᵏ) < O(2ᴺ)
1.4 파이썬 언어에 대한 기본적인 지식
클래스와 메소드
파이썬 언어는 객체지향 프로그래밍 언어로써 Class를 선언하여 객체에 데이터를 저장하고 Method를 선언하여 객체들에 대한 연산을 구현한다.
class Student: def __init__(self, name, id): self.name = name self.id = id def get_name(self): return self.name def get_id(self): return self.id best = Student('caution', 101) print(best.get_name()) print(best.get_id())-
def 를 통해 함수를 정의할 수 있다. 클래스 내부에 정의하면 메소드, 클래스 외부에 정의하면 함수이다.
-
객체 생성자는 클래스 내부에 선언하며 init 으로 정의한다.
-
self 는 클래스 인스턴스를 의미하며 모든 메소드의 첫 번째 인자로 self를 받는다.
- 인스턴스 인자의 이름을 self 대신 다른 이름을 써도 무방하지만 관례상 self를 쓴다.
-
self를 쓰지만 실제 함수를 호출할때는 이를 생략한다.
- best.get_name() => get_name(best)
리스트 선언 및 관련 연산 수행
a = [] # 비어있는 리스트 a 선언 b = [None] * 10 # 크기가 10이고 각 원소가 None으로 초기화된 리스트 c = [40, 10, 70, 60] # 크기가 4이고 4개의 정수로 초기화된 리스트 print(c[0]) # 40 print(c[-1]) # 60 c.pop() # 리스트 마지막 항목인 60 제거 c.pop(0) # 리스트 0번째 항목인 40 제거 c.append(90) # 리스트 맨 뒤에 90 추가 print(len(c)) # len() -> length 3- 리스트는 동적 배열로 새 항목이 추가되거나 삭제되는 자동으로 리스트의 크기를 조절한다. *
조건문
if 조건식: 명령문 elif 조건식: 명령문 else: 명령문반복문
for 조건식 in 리스트: 명령문 for 변수 in range(N): 명령문 while 조건식: 명령문- range(start, N, step)
- range(10) : 0…9
- range(5, 10) : 5…9
- range(0, 10, 2) : 0, 2, 4, 6, 8
- range(10, 1, -1): 10, 9, … 2
난수값을 가지는 배열 만들기, 시간 측정하기
import random import time random.seed(time.time()) # 난수 생성을 위한 초기값은 현재 시간으로 한다. a = [] for i in range(100): # 100번 난수를 생성해서 넣을거양 a.append(random.randint(1, 1000)) # 1과 1000 사이의 난수를 생성하여 배열에 추가 start_time = time.time() # 여기에 측정이 필요한 알고리즘을 넣는다. print("-- %s second ---", (time.time() - start_time))내장 함수
- ord(‘문자’) : 문자의 Unicode 값을 리턴
- list(reversed(리스트)) : 역순으로 된 리스트를 리턴한다.
- 리스트.revers() : 리스트를 역순으로 만든다.
lambda
함수의 이름도 return 도 없이 수행되는 함수로, 간단한 함수를 대신할 수 있다.
lambda 인자(arguements): 수행식(expression)filter() 혹은 map() 함수의 인자로 많이 사용된다.
lambda와 filter, map
a = [1, 5, 4, 6, 8, 11, 3, 12] even = list(filter(lambda x: (x%2 == 0), a)) print(even) # [4, 6, 8, 12] ten_times = list(map(lambda x: x * 10, a)) print(ten_times) # [10, 50, 40, 60, 80, 110, 30, 120] b = [[0,1,8], [7,2,2], [5,3,10], [1,4,5]] b.sort(key = lambda x: x[2]) print(b) # [7, 2, 2], [1, 4, 5], [0, 1, 8], [5, 3, 10]1.5 순환 : 재귀호출
함수의 실행 과정 중 스스로를 호출하는 것을 말한다. 팩토리얼, 조합을 계산하기 위한 식의 표현, 무한한 길이의 숫자 스트림 만들기, 트리 자료구조, 프랙털 등의 기본 개념으로 사용한다.
무한 호출을 방지할 수 있도록 스스로의 호출을 중단시킬 수 있는 조건문을 넣어주어야 한다.
- 기본 case : 더 이상 스스로를 호출하지 않는 부분
- 순환 case : 스스로를 호출하는 부분
무한 호출을 방지하기 위해 선언한 변수 혹은 수식의 값이 호출이 일어날 때마다 순환 case에서 변동되어 최종적으로는 if-문의 조건식에서 기본 case를 실행하도록 짜야 한다.
def recurse(): print(' *') recurse() recurse() # RecursionError가 발생한다. def recuser(count): if count <= 0: # 0보다 작거나 같을 경우 .을 찍어준다. 이 경우가 기본 case print('.') else: # 0보다 클 경우 : 순환 case print(count, ' *') # count와 *을 찍어준다. recurse(count-1) # count - 1 을 인자로 자기자신을 호출한다. recurse(5)팩토리얼 예제
1) 순환으로 풀기
def factorial(n): if n <= 1: return 1 # 기본 case else: return n*factorial(n-1) # 순환 case print(factorial(4))2) 반복문으로 풀기
factorial = 1 for i in range(1, 5): factorial *= o print(factorial)반복문을 이용한 계산은 함수 호출로 인해 시스템 스택을 사용하지 않으므로 순환을 이용한 계산보다 간단하며 메모리도 적게 사용한다.
함수의 마지막 부분에서 순환하는 것을 꼬리 순환 이라고 하며, 이는 반복문으로 변환하는 것이 수행 속도와 메모리 사용 측면에서 효율적이다. 하지만 모든 꼬리 순환을 반복문으로 바꾸기 어렵거나 적합하지 않은 경우도(트리 전체 탐색 등) 존재한다.
트리 탐색 예제
섬의 구조가 트리 형태로 연결되어 있다고 할 때, 이 나라의 관광청에서는 모든 섬을 방문할 수 있는, 순서가 다른 3 개의 관광코스를 만들었다.
- A 코스 : 시작 섬을 관광하고, 왼쪽 섬으로 관광을 진행한다. 왼쪽 방향의 모든 섬을 방문하면 오른쪽 섬을 관광한다.
- B 코스 : 시작 섬은 관광하지 않고, 왼쪽의 모든 섬 관광을 진행하고 나서 시작 섬을 관광한다. 이후에 오른쪽 섬의 관광을 진행한다.
- C 코스 : 시작 섬은 관광하지 않고, 왼쪽의 모든 섬 관광을 진행하고 오른쪽의 모든 섬 관광을 진행한다. 이후 시작 섬을 관광한다.
class Island: def __init__(self, name, left=None, right=None): self.name = name self.left = left self.right = right def initMap(): n1 = Island('H') n2 = Island('F') n3 = Island('S') n4 = Island('U') n5 = Island('E') n6 = Island('Z') n7 = Island('K') n8 = Island('N') n9 = Island('A') n10 = Island('Y') n11 = Island('T') n1.left = n2 n1.right = n3 n2.left = n4 n2.right = n5 n3.left = n6 n3.right = n6 n4.left = n7 n4.right = n8 n5.left = n9 n7.right = n10 n9.right = n11 return n1 def A_course(n): if n is not None: print(n.name, '->', end='') # 섬 방문 A_course(n.left) # 왼쪽 섬 방문 A_course(n.right) # 오른쪽 섬 방문 def B_couser(n): if n is not None: B_course(n.left) # 왼쪽 섬 방문 print(n.name, '->', end='') # 섬 방문 B_course(n.right) # 오른쪽 섬 방문 def C_couser(n): if n is not None: C_course(n.left) # 왼쪽 섬 방문 C_course(n.right) # 오른쪽 섬 방문 print(n.name, '->', end='') # 섬 방문
-
2018 WWDC 정리 : High Performance Auto Layout
2018 WWDC 정리 : High Performance Auto Layout
어떻게 AutoLayout 을 작성해야 더 나은 성능을 낼 수 있을까? 를 확인하려면 내부적으로 Constraint 를 사용할 때 어떻게 작동하는지에 대해서 생각해봐야 한다.
화면이 그려질 때마다 Constraint 를 모두 제거했다가 다시 생성한다면?
Update Constraint 함수는 Render loop에 속해있습니다.
Render Loop는 매초 120 회 실행되는 프로세스입니다. Reder loop를 통해 각 프레임마다 모든 콘텐츠를 보여줄 수 있습니다. Render loop는 제약 조건, 레이아웃 및 표시 업데이트의 세 단계로 구성됩니다.

이러한 함수들은 매 프레임마다 호출될 수 있으며, 1 초에 120 프레임을 실행하기 때문에 위와 같은 케이스에서는 많은 문제가 발생할 수 있습니다.
- Render loop는 필요하다면 유용하지만, 너무 많이 호출되니까 너무 민감한 코드는 쓰지말고 이왕이면 Interface Builder 를 사용하자.
- 코드로 작성한다면 매번 Constraint 를 새로 작성하지 말고 Constraint 가 작성되는 부분은 한 번만 호출되도록 변경하자.
Activating a Constraint
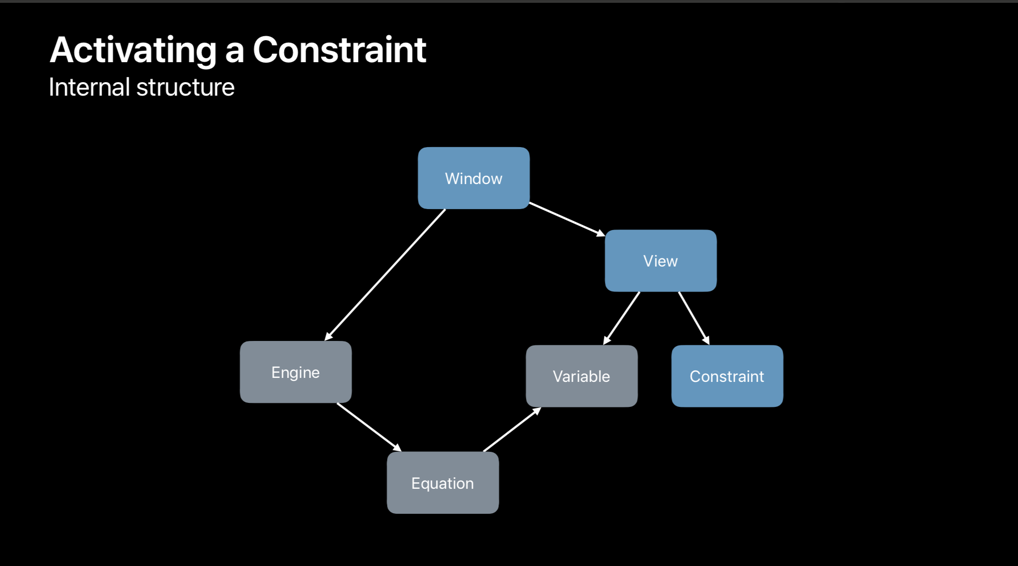
View 는 Window에 붙어있고, Window는 엔진과 연결되어 있으며, 이 엔진이 오토 레이아웃의 핵심입니다. View에 제약 조건이 부여되면, 제약 조건에 해당하는 방정식을 만들고 엔진에 방정식을 추가합니다.
방정식에는 최소 X, 최소 Y, 너비 및 높이의 네 가지 변수가 있으며 엔진은 이를 주어진 방정식을 기준으로 계산합니다. 새로운 제약조건이 활성화 되면 엔진이 다시 변수를 계산하고 다음 Render loop 때 이 변경값을 반영합니다.
엔진은 레이아웃에 대한 캐시값을 저장하고 있고 지속적으로 레이아웃 요소들을 tracking 하고 있습니다.
Building a More Performance Layout
Model the problem naturally
두 개의 레이아웃에 대한 컨스트레이트를 하나로 작성하지 말고 각각 고유의 컨스트레인트를 주는 것이 좀 더 직관적이며 효율적입니다.
View를 제거하는 것보다는 hidden 설정을 주는 것이 비용이 적게 듭니다.
비슷한 형태의 reusable cell 이라면 view를 공통으로 사용하고 hidden을 사용하는 건 어떨까요?
제약 조건을 지우고 새로 추가 하는 것보다는 기존이 제약조건을 수정하는 것이 낫습니다.
Constraint Churn
- Avoid removing all constraints
- Add static constraints once
- Only change ther constraints that need changing
- Hide views instead of removing them.
-
왜 HIG를 알아야할까?
나는 프로그래머인데 왜 H.I.G를 알아야할까?
H.I.G는 Human Interface Guidelines의 약자입니다. 앱의 사용성을 강화하고 사용자에게 더 나은 경험을 선사하기 위해서는 개발을 시작하기 전 공통적인 디자인 개념과 권장 사항을 숙지하는 것이 좋습니다. Apple의 HIG를 숙지하고 적용하는 것만으로도 앱의 전체적인 디자인부터 사용자 경험의 완성도까지 향상시킬 수 있습니다.
iOS 는 디바이스들이 한정되어 있기 때문에 아이콘이나 레이아웃이 일정합니다. HIG에서 제시되는 UI 규격을 맞추어주면 사용자들이 앱을 사용할 때 좀 더 익숙하고 사용성이 높다고 느낄 수 있습니다. UX도 마찬가지입니다. Leading edge에서 slide할 경우 뒤로 돌아가는 것, 확인/취소 버튼의 배치, 액션 시트에서 취소 버튼은 항상 하단에 있어야 하고 파괴적인 행동(삭제 등)에 대해서는 적색을 사용하고 상단에 표시해야한다는 등 이미 iOS 플랫폼에 익숙한 사용자들에게 상이한 경험을 제공한다면 이 앱을 불편하다고 느낄 수 있습니다.
또한 HIG를 읽고 있자면, 모든 UI, UX 요소들이 다 각각의 의미를 가지고 있다는 것을 알 수 있습니다. 모든 동작에 유효한 사용자 경험을 제공하는 것은 매우 중요하다고 생각합니다!
앱을 사용하는 사용자가 편안하고 익숙하게 앱을 사용할 수 있다는 것, 즉 사용성이 높아야 이 앱이 흥하고 그럼 개발자도 흥할 수 있습니다! (오예) 개인적인 생각입니다만, 기존의 Apple App들을 살펴보았을 때 특별한 디자인 없이 기존 Apple Cocoa Framework에서 제공하는 기본 UI요소들만으로도 짱짱 완성도 높아보이는 앱을 만들 수 있습니다. HIG를 적용하면 적어도 무지개색 + 형광색 컬러셋에 보노보노가 그려진 디자인 같은 요상한 디자인보다는 나은 결과물이 나오지 않을까요 하하.
-
Hello Docker
한영님과 함께하는 Docker 기초!
참고 문서
도커에 대한 개념은 첫 번째 링크가 아주 잘 정리해주었다 :) 나는 실습위주로 정리.
프로그램 설치
Python 설치 확인
$ brew list $ python3 --versionpython 은 기본적으로 python version 2 를 말하고 python3 는 version 3를 말한다!
python에서 소프트웨어 관리하는 패키지 관리 시스템인 pip(Python Package Index)도 pip 는 version 2, pip3 는 version 3 를 말한다.
Django 프로젝트 설치
Get started with Docker Desktop for mac 에 보면 nginx 기반의 boilerplate 프로젝트가 있는 것 같지만 Django 해보고 싶으니까 Django 설치해보자!
requirements.txt 만들기
얘는 왜 만들어보냐면 도커가 개발환경에 필요한 패키지들을 묶어서 이미지화 하고 그걸 이용해서 동일한 환경을 복제하기 쉽도록 만들어주는데 이미 이전부터 pip3 freeze / install 을 이용하면 패키지 목록을 파일에 저장하고 이 파일을 이용해서 패키지들을 재설치 할 수 있었다. 이런게 있었다 + 뒤에 가서 쓸거다.
- pip3 list : 현재 환경에 설치된 패키지 목록 조회
- pip3 freeze : 현재 환경 내에 설치된 패키지 목록을 특정 파일에 기록
- pip3 install : 파일에 저장된 패키지 목록을 설치
$ pip3 list $ pip3 freeze > requirements.txt $ cat requirements.txt Django==2.1.5 pytz==2018.9 $ pip3 install requirements.txtDocker Desktop 설치
Django 프로젝트 로컬 서버로 올리기
프로젝트 생성
$ django-admin startproject blog위 명령어로 쟝고 템플릿 프로젝트를 생성할 수 있다. 프로젝트 이름이 blog!
만들어진 프로젝트는 기본적으로 다음과 같은 구조를 가진다.
blog ├── manage.py └── blog ├── __init__.py ├── settings.py ├── urls.py └── wsgi.pyDjango 프로젝트 서버 올려보기
blog 프로젝트에 기본적으로 생성되는 manage.py 파일을 통해 Django 프로젝트를 서버에 올릴 수 있다.
$ python3 blog/manage.py runserver Performing system checks... System check identified no issues (0 silenced). You have 15 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. Run 'python manage.py migrate' to apply them. February 07, 2019 - 04:05:00 Django version 2.1.5, using settings 'blog.settings' Starting development server at http://127.0.0.1:8000/ Quit the server with CONTROL-C.ip 주소와 포트를 설정해주지 않으면 기본적으로 127.0.0.1:8000 으로 연결된다. python [name]/manage.py runserver [ip:port_number] 로 설정해줄 수 있다.
브라우저를 켜고 localhost:8000 으로 접속하면 쟝고 프로젝트의 개발버전(디폴트)이 올라간걸 알 수 있다!
화면 추가하기
Django에 화면을 추가하려면 화면을 구성할 .py 파일을 만들고 이를 urls.py 에 등록해주어야 한다.
views.py
from django.http.response import HttpResponse def index(request): return HttpResponse('<h1>Hello Django!</h1>')이미 만들어져 있는 urls.py 파일에 우리가 만든 views.py파일에서 정의한 index 를 import 하고 url patterns 에 추가한다.
urls.py
from django.contrib import admin from django.urls import path from .views import index urlpatterns = [ path('admin/', admin.site.urls), path('', index), ]쟝고 프로젝트에 대한 추가적인 이해는 Django Documentation - Tutorial 을 참고하자!!!
이제 서버를 다시 올리면 (서버를 내리려면 Control+C) 아까의 로켓은 없어지고 Hello Django! 가 나온당! 우왕.
Docker 사용해보기
Docker Image 사용하여 서버 올리기
자 이제 이걸 Docker 를 사용해서 해보자. 우리는 이미 로컬에 python을 깔았지만, Docker를 통해 가상의 python 환경을 만들어내고 그 위에 서버를 띄워보자.
이미 많은 OS의 Docker Image들이 존재한다. 우리가 사용할 python 공식 Image는 Docker Hub 에서 찾을 수 있다.
Docker Hub에서 제공하는 python image들은 같은 버전임에도 다른 태그를 가진 이미지들이 존재한다. 자세한 설명은 Docker Docs 에서 확인 가능하다!
- Alpine : Alpine Linux
- Stretch : Debian Linux의 특정 버전
- Slim : Debian Linux의 특정 버전의 최소용량버전
정확히는 나도 더 공부하는 걸로!
암튼 우리는 python:3.7.2-slim 을 사용할거드앙.
$ docker images $ docker run --rm -it python:3.7.2-slim /bin/bash# pip install django # django-admin startproject blog # python blog/manage.py runserver와! 도커를 이용해서 가상컨테이너에 python을 실행하고 그 안에서 django 를 설치한 뒤 프로젝트를 만들고 서버를 올렸다!
그치만 확인할 방법이 없는걸?! 그럼 도커랑 로컬을 연결할 수 있게 포트를 설정해주자.
$ docker run --rm -it -p 7999:8000 python:3.7.2-slim /bin/bash# pip install django # django-admin startproject blog # python blog/manage.py runserver 0:8000그럼 이제 localhost:7999 로 접속하면 docker의 8000 포트로 연결되어서 Django 프로젝트 화면이 나오게 된다.
Docker Image 생성
하지만! 도커는 가상머신이니까 내렸다 올렸다 할 때마다 다시 초기화 되서 매번 Django를 설치하고 프로젝트를 만들어야 하잖아?! 짱짱 귀찮으니까 자동화를 해보자.
도커 이미지를 실행할 때 자동으로 해야할 일들을 Dockerfile로 정의해주자. 이 도커파일은 우리가 전에 만들었던 Django 프로젝트의 하위에 있다. blog/Dockerfile (manage.py랑 같은 위치)
Dockerfile : 대소문자 주의, 확장자 없음 주의! 도커파일은 그냥 도커파일이다!
FROM python:3.7.2-slim MAINTAINER caution.dev@gmail.com RUN pip install django WORKDIR /root RUN django-admin startproject blog WORKDIR /root/blog CMD python manage.py runserver 0:8000한 줄 씩 설명하자면 다음과 같다.
이 Docker Image는 python:3.7.2-slim 을 사용한다. python:3.7.2-slim 이미지에 Dockerfile이 있다면 거기에 정의된 명령어들을 수행할거다!
MAINTAINER : 이 Docker Image를 관리하는 관리자의 이메일 주소다!
RUN : 다음 명령어를 수행할거다! 여기서는 django를 설치한다.
WORKDIR : 작업을 수행할 디렉토리를 /root로 변경할 거야! (cd 로 경로 이동하는 거랑 비슷)
RUN : 다음 명령어를 수행할거다! 여기서는 django 프로젝트를 생성한다.
WORKDIR : 작업을 수행할 디렉토리를 /root/blog 로 변경할거야!
CMD : 컨테이너가 시작되었을 때 수행할 명령. Dockerfile에서 한 번만 사용할 수 있다. 여기서는 서버를 띄운다.
Dockerfile을 다 만들었으면 이제 Docker Build 를 수행하여 Docker Image를 만든다.
$ docker build -t blog . $ docker imagesdocker images 명령어를 통해 만들어진 image 들을 확인할 수 있다.
자 이제 다시 docker를 실행시켜보자!
docker run --rm -it -p 7999:8000 blog우왕 그러면 자동으로 django가 켜지고 서버까지 켜지는 걸 확인할 수 있다. localhost:7999 를 열면? 아마 로케트가 나올거다!
local 파일을 이용하여 docker에 서버 올리기
그런데 위에껄 하면 매번 새로운 프로젝트가 생성되고 그걸 켠다. 그럼 매번 컨테이너 내려가면 데이터 다 날아가는데 껏다 킬때마다 0부터 다시 코딩해야 한다. WHF!!!!!!!!!!!!!!!!
그러려고 만든 Docker가 아니니까, 우리가 이미 로컬에 만들었던 프로젝트를 이용해서 Docker에 올려보자.
Dockerfile 을 수정한다.
FROM python:3.7.2-slim MAINTAINER caution.dev@gmail.com COPY blog/requirements.txt /tmp/requirements.txt RUN pip install -r /tmp/requirements.txt COPY . /root/app WORKDIR /root/app/blog CMD python manage.py runserver 0:8000새로운 명령어인 COPY가 생겼다. 이건 그야말로 로컬에 있는 파일을 Docker 로 복사할 때 사용한다.
앞서 만들었던 requirements.txt에는 django 를 포함한 현재 환경에서 사용되는 패키지들이 정의되어 있다. 그래서 이 파일을 복사한 뒤 RUN 명령어를 통해 이 파일에 있는 패키지들을 docker에서 설치한다. (결론적으로는 그러니까 장고를 설치해줄거다!)
그리고 현재 로컬에서 만들었던 Django project 를 그대로 복사한다. 매번 Django 프로젝트를 새로 생성하지 않고 로컬에서 작업한 내용을 가져다가 쓸 것이다. 0부터 코딩을 다시 할 필요가 없다!
Dockerfile을 수정했으면 다시 Docker Build 로 image를 새로 만들고 Docker를 실행시켜 보자.
$ docker build -t blog . $ docker run --rm -it -p 7999:8000 blog이제 localhost:7999 를 열면? 로케트가 아닌 Hello Django! 가 나올거다!
우와! 이제 제대로 로컬에서 Docker를 써봤다. 하지만 우리는 로컬서버를 돌리는 게 아니니까 (….) 의미가 없……진 않지만 실제 서버처럼 해보자. 한영님은 EC2를 이용하기로 했으니까 해본다.
EC2 만들기